使用 Trino 和 Ceph 对象存储 S3 Select 进行 TPC-DS 基准测试
简介 ¶
在本文中,我们分析了使用启用 Ceph 对象 S3 Select 功能的 Trino 进行的性能基准测试结果,使用了 1TB 和 3TB 规模的 TPC-DS 基准测试查询。我们证明,平均而言,查询运行速度提高了 2.5 倍。在某些情况下,我们实现了九倍的改进,与未使用 S3 Select 功能的 Trino 相比,网络数据处理量减少了 144TB。将 IBM Storage Ceph 的 S3 Select 与 Trino/Presto 结合使用,可以增强数据湖性能,降低成本,并简化组织的数据访问。
我们感谢 Gal Salomon 和 Tim Wilkinson 进行了 TPC-DS 基准测试,并向我们提供了这些结果。

什么是 Trino? ¶
Trino 是一种分布式 SQL 查询引擎,允许用户使用单个 SQL 语句查询来自多个数据源的数据。它直接在数据湖上提供类似数据仓库的功能。
Trino、Presto 和 PrestoDB 之间有什么区别? ¶
您可能遇到过对 Trino、Presto 和 PrestoDB 的引用,它们都源自同一个项目。Presto 是 Facebook 最初的项目,于 2013 年开源。PrestoSQL 于 2018 年成为一个社区驱动的开源项目,并在 2020 年更名为 Trino。
Presto 是数据工程师的必备工具,他们需要为他们的更高层次的商业智能 (BI) 工具提供快速查询引擎。
为什么选择 Ceph 作为 S3 对象存储? ¶
- Ceph 为本地部署提供了一流的、高度兼容的 S3 API。
- Ceph 充满信心地满足了关键大规模安装的需求以及对数据日益增长的需求。它的性能随着容量的扩展而扩展,从而节省了大量成本,并能够管理指数级的数据增长。
Ceph 为 Trino、Presto 等数据查询工具带来了哪些增强? ¶
Ceph 提供了 S3 API S3 Select 功能。S3 Select 显著提高了存储在 S3 兼容对象存储中的数据的 SQL 查询效率。通过将查询推送到 Ceph 集群,S3 Select 可以显著提高性能,更快地处理查询,并最大限度地减少网络和 CPU 资源成本。S3 Select 和 Trino 都是水平可扩展的,可以处理不断增加的数据量和用户查询,而不会牺牲性能。Trino 对 SQL 和 S3 Select 查询数据原地的能力的支持,使用户能够在无需复杂的数据移动或转换任务的情况下访问和分析数据。
Ceph 的对象数据中心-数据传输网络 (D3N) 功能使用高速存储,例如 NVMe SSD 或 DRAM,以缓存访问侧的数据集。D3N 通过加速从数据湖或湖仓的重复读取来提高在大数据集群中运行的作业的性能。
使用 Ceph + Trino 的 TPC-DS 基准测试 ¶
测试流程 ¶
我们执行了以下 72 个 TPC-DS 查询,规模分别为 1TB、2TB 和 3TB,以表征性能和资源消耗。数据集采用未压缩的 CSV 格式。我们多次执行每个查询,并启用和禁用 S3 Select,并通过监控每次运行的标准差来确保结果一致。
如果您有兴趣进一步了解此主题,请查看 Gal Salomon 的 GitHub 仓库,您将在其中找到有关使用 Trino 和 Ceph 设置测试环境的说明。还提供了用于此基准测试的 TPC-DS 基准测试工具的说明。
测试环境 ¶
基准测试使用的硬件如下
- Trino 客户端(驱动程序)节点
- Trino 版本:405
- 3x Dell R630
- 2x E5-2683 v3(总共 28 个内核,56 个线程)
- 128 GB RAM
- Ceph 集群节点
- 操作系统:RHEL9.2
- Ceph 版本:18.2.0-110.el9cp (Reef)
- 3x Dell R630 监控/管理器节点
- 2x E5-2683 v3(总共 28 个内核,56 个线程)
- 128 GB RAM
- 8x Supermicro 6048R OSD / RGW 节点
- 2x Intel E5-2660 v4(总共 28 个内核,56 个线程)
- 256 GB RAM
- 192x BlueStore OSD
- 每个节点 24 个 2TB HDD
- 每个 OSD 节点 2 个 800G NVMe SSD 用于 WAL/DB
可调参数 ¶
调整了以下 S3 Select 设置
- hive.max-split-size 分配给工作程序的单个文件部分的最大大小。较小的拆分会导致更多的并行性,从而可以减少延迟,但会增加开销并增加系统负载。测试从 4MB、8MB、16MB、32MB、64MB 和 128MB 值开始,但最终我们为所有测试选择了 128MB。
- hive.max-splits-per-second 每个表扫描生成的每秒拆分的最大数量。可用于减少存储系统的负载。没有默认限制,因此 Trino 会最大限度地提高数据访问的并行性。所有测试均使用 10K 设置执行。
并发性 ¶
Trino 引擎通过将原始查询划分为多个并行 S3 Select 请求来处理复杂的查询。这些请求将请求的表(S3 对象)划分为相等的范围,然后将其分发到 Ceph 集群的 RGW 服务。负载均衡器有效地将请求通道化到 Ceph 对象网关,确保我们数据处理需求的最佳性能和可扩展性。

测试结果 ¶
下一部分提供了 TPC-DS 基准测试结果的概述。这些结果有助于我们了解 Ceph 对象 S3 Select 功能在使用 CSV 数据集时带来的实质性好处。这些好处包括改进的查询时间和减少的数据处理。我们包含了一个图表,显示了使用 S3 Select 实现的总网络流量减少量。我们可以通过使用此功能节省 144TB 的网络流量。

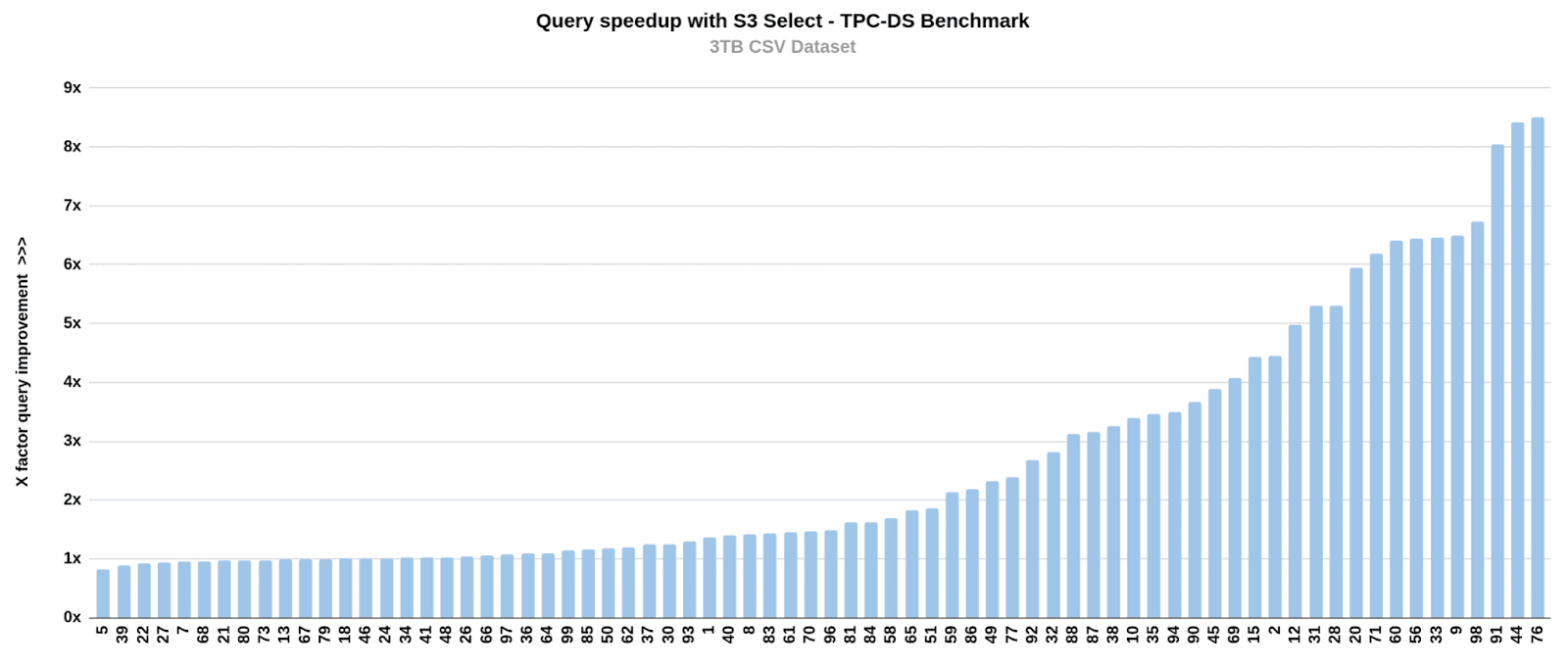
下图显示了使用 3TB 规模数据集的 S3 Select 实现的每个查询的速度提升。X 轴值是来自上述仓库的查询编号,Y 轴值是每个查询的速度提升。在测试期间,我们观察到启用 S3 Select 改进了所有 72 个查询。速度提升最大的查询速度提高了 9 倍,总体平均提升约为 2.5 倍。

启用 S3 Select 时,我们将计算工作卸载到 Ceph 对象网关,因此正如预期的那样,在启用 S3 Select 的情况下执行查询时,它们会看到 CPU 使用率增加。但是,CPU 利用率保持在可接受的水平。启用 S3 Select 后的内存需求几乎没有增加,平均增加 2.50%。分块可以处理任何大小的对象,因为它以块的形式进行,而无需预加载整个对象。

查询编号 9 能够将网络数据处理量减少 18TB。在所有 72 个查询中,启用 S3 Select 后,处理数据的总减少量为 144 TB。

总结和下一步计划 ¶
在本文中,我们分享了我们的基准测试结果,我们在 1TB 和 3TB 规模下运行了 72 个 TPC-DS 查询。我们发现,利用 Ceph 对象 S3 Select 推送性能优化可以使查询比以前更快地完成,同时显著降低资源需求。使用 Trino 和 S3 Select,您可以将投影和预测操作的计算工作推送到 Ceph,从而提高查询运行时间最多 9 倍,平均提高 2.5 倍。这显著减少了网络上的数据传输,为执行的 72 个查询节省了 144TB 的网络流量。通过将 Ceph S3 Select 与 Trino 和 Presto 结合使用,组织可以增强数据湖性能,降低成本,并简化数据访问。
作者感谢 IBM 对社区的支持,为我们提供时间来创建这些帖子。