Ceph Stretch 集群第 3 部分:处理故障
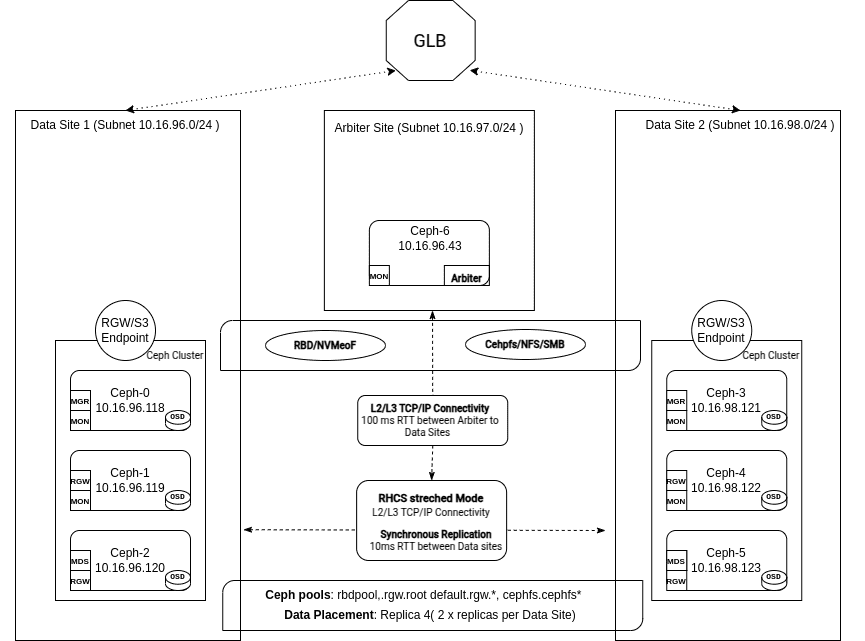
两站点 Stretch 集群:处理故障 ¶
在 第 2 部分 中,我们探讨了使用自定义服务定义文件、CRUSH 规则和服务的放置来手动部署一个两站点 Ceph 集群,并配备了一个仲裁站点和 Monitor。
在本期最后一篇中,我们将通过检查整个数据中心发生故障时会发生什么来测试该配置。
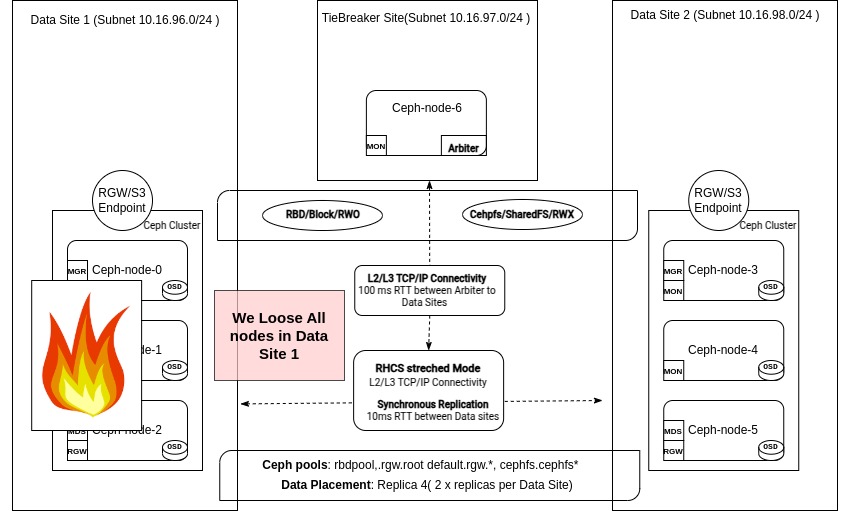
简介 ¶
任何两站点 Stretch 集群设计的关键目标是确保即使一个数据中心离线,应用程序也能保持完全运行。通过同步复制,集群可以透明地处理客户端请求,即使在完全站点故障期间,也能保持零恢复点目标 (RPO),并防止数据丢失。
本系列第三篇也是最后一篇帖子将探讨 Ceph 如何自动检测和隔离故障数据中心。集群过渡到Stretch 降级模式,仲裁 Monitor 确保仲裁。在此期间,复制约束会暂时调整,以在幸存站点保持服务可用。
一旦离线的数据中心恢复,我们将演示集群如何无缝恢复其完整的 Stretch 配置,恢复完全冗余和同步操作,而无需手动干预。最终用户和存储管理员在整个过程中体验到最小的干扰和零数据丢失。
我们丢失了一个整个数据中心! ¶
集群工作正常,我们的 Monitor 处于仲裁状态,并且我们 PG 的活动集包括四个 OSD,每个站点两个。我们的池配置了复制规则,size=4,和 min_size 2。
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_OK
services:
mon: 5 daemons, quorum ceph-node-00,ceph-node-06,ceph-node-04,ceph-node-03,ceph-node-01 (age 43h)
mgr: ceph-node-01.osdxwj(active, since 10d), standbys: ceph-node-04.vtmzkz
osd: 12 osds: 12 up (since 10d), 12 in (since 2w)
data:
pools: 2 pools, 33 pgs
objects: 23 objects, 42 MiB
usage: 1.4 GiB used, 599 GiB / 600 GiB avail
pgs: 33 active+clean
# ceph quorum_status --format json-pretty | jq .quorum_names
[
"ceph-node-00",
"ceph-node-06",
"ceph-node-04",
"ceph-node-03",
"ceph-node-01"
]
# ceph pg map 2.1
osdmap e264 pg 2.1 (2.1) -> up [1,3,9,11] acting [1,3,9,11]
# ceph osd pool ls detail | tail -2
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
我们将为每个阶段显示一个图表,以描述故障期间的各种阶段。
此时,发生了一些意外情况,我们失去了对 DC1 中所有节点的访问权限
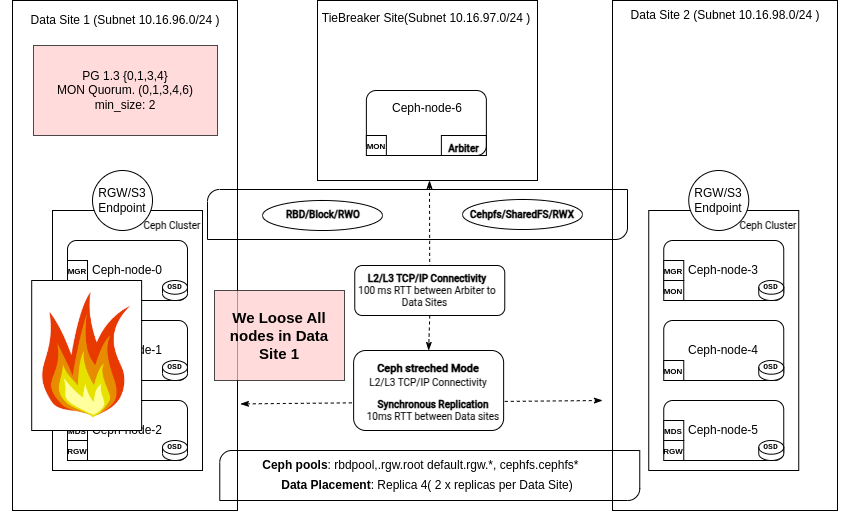
以下是来自剩余站点的一个 Monitor 日志摘录:DC1 中的 Monitor 被认为 down,并从仲裁中移除
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : [WRN] MON_DOWN: 2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-00 (rank 0) addr [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] is down (out of quorum)
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-01 (rank 4) addr [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] is down (out of quorum)
在 DC2 中的 ceph-node-03 上运行的 Monitor 调用进行 Monitor 选举,提议自己,并被接受为新的领导者
2025-02-18T14:14:33.087+0000 7f0548201640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 calling monitor election
2025-02-18T14:14:33.087+0000 7f0548201640 1 paxos.3).electionLogic(141) init, last seen epoch 141, mid-election, bumping
2025-02-18T14:14:38.098+0000 7f054aa06640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 is new leader, mons ceph-node-06,ceph-node-04,ceph-node-03 in quorum (ranks 1,2,3)
每个 Ceph OSD 会以小于六秒的随机间隔对其他 OSD 进行心跳检测。如果对等 OSD 未在 20 秒的宽限期内发送心跳,则检查的 OSD 会认为对等 OSD down,并将此报告给 Monitor,Monitor 将更新集群映射。
默认情况下,来自不同主机的两个 OSD 必须向 Monitor 报告另一个 OSD 处于关闭状态,Monitor 才会确认故障。这有助于防止误报、闪烁和级联问题。但是,所有报告的 OSD 可能会托管在一个受故障交换机影响的机架中,该交换机影响与其他 OSD 的连接。为了避免误报,我们将报告的对等方视为一个可能存在问题的子集群。
Monitor OSD 报告器子树级别根据 CRUSH 映射中的共同祖先类型将对等方分组到子集群中。默认情况下,需要来自不同子树的两个报告才能声明 OSD 处于关闭状态。
2025-02-18T14:14:29.233+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 prepare_failure osd.0 [v2:192.168.122.12:6804/636515504,v1:192.168.122.12:6805/636515504] from osd.10 is reporting failure:1
2025-02-18T14:14:29.235+0000 7f0548201640 0 log_channel(cluster) log [DBG] : osd.0 reported failed by osd.10
2025-02-18T14:14:31.792+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 we have enough reporters to mark osd.0 down
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 2 osds down (OSD_DOWN)
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 host (2 osds) down (OSD_HOST_DOWN)
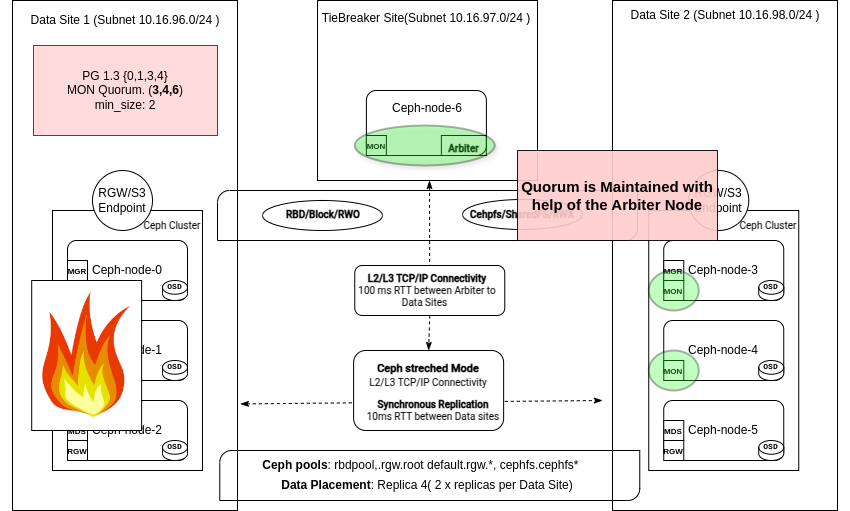
在 ceph status 命令的输出中,我们可以看到仲裁由 ceph-node-06、ceph-node-04 和 ceph-node-03 维护
# ceph -s | grep mon
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
mon: 5 daemons, quorum ceph-node-06,ceph-node-04,ceph-node-03 (age 10s), out of quorum: ceph-node-00, ceph-node-01
我们通过 ceph osd tree 命令看到 DC1 中的 OSD 被标记为 down
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
0 hdd 0.04880 osd.0 down 1.00000 1.00000
1 hdd 0.04880 osd.1 down 1.00000 1.00000
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 down 1.00000 1.00000
7 hdd 0.04880 osd.7 down 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 down 1.00000 1.00000
5 hdd 0.04880 osd.5 down 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
4 hdd 0.04880 osd.4 up 1.00000 1.00000
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
10 hdd 0.04880 osd.10 up 1.00000 1.00000
11 hdd 0.04880 osd.11 up 1.00000 1.00000
-9 0.09760 host ceph-node-05
8 hdd 0.04880 osd.8 up 1.00000 1.00000
9 hdd 0.04880 osd.9 up 1.00000 1.00000
当整个站点发生故障时,Ceph 会引发 OSD_DATACENTER_DOWN 健康警告。这表明由于网络中断、电源故障或其他问题,一个 CRUSH datacenter 无法使用。来自 Monitor 日志
2025-02-18T14:14:32.910+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 datacenter (6 osds) down (OSD_DATACENTER_DOWN)
我们也可以从 ceph status 命令中看到。
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_WARN
3 hosts fail cephadm check
We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
1 datacenter (6 osds) down
6 osds down
3 hosts (6 osds) down
Degraded data redundancy: 46/92 objects degraded (50.000%), 18 pgs degraded, 33 pgs undersized
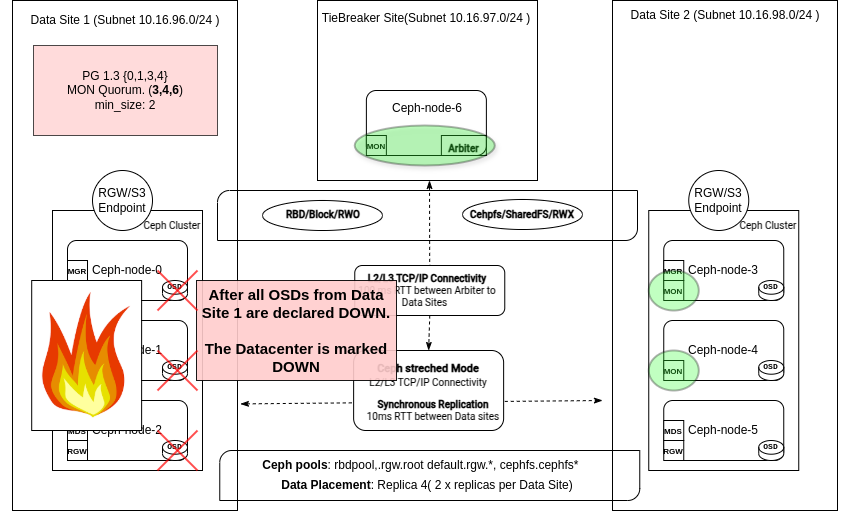
在两站点 Stretch 场景中,当整个数据中心发生故障时,Ceph 进入Stretch 降级模式。 您会在 Monitor 日志中看到类似这样的条目
2025-02-18T14:14:32.992+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : Health check failed: We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer (DEGRADED_STRETCH_MODE)
Stretch 降级模式 ¶
Stretch 降级模式是自我管理的。当 Monitor 确认整个 CRUSH 数据中心无法访问时,它就会启动。管理员无需手动提升或降级任何站点或 DC。Ceph 的编排器会自动更新 OSD 映射和 PG 状态。一旦集群进入降级 Stretch 模式,操作就会自动展开。
Stretch 降级模式意味着 Ceph 不再需要来自故障数据中心中的离线 OSD 的确认才能完成写入或将放置组 (PG) 变为活动状态。
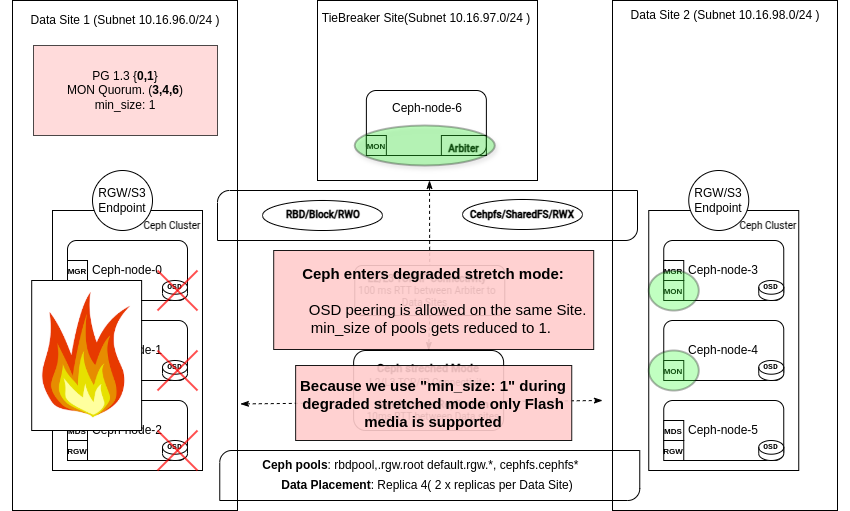
Stretch 模式对等规则放宽 ¶
在 Stretch 模式下,Ceph 实施了一个特定的 Stretch 对等规则,该规则要求至少有一个来自每个站点的 OSD 参与活动集,才能将放置组 (PG) 从对等状态过渡到 active+clean。此规则可确保如果一个站点完全离线,则不会确认新的写入操作,从而防止脑裂场景并确保一致的站点复制。
进入降级模式后,Ceph 会暂时修改 CRUSH 规则,以便仅需要幸存站点来激活 PG,从而允许客户端操作无缝继续。
# ceph pg dump pgs_brief | grep 2.11
dumped pgs_brief
2.11 active+undersized+degraded [8,11] 8 [8,11] 8
所有池的 min_size 降低到 1 ¶
当一个站点离线时,Ceph 会自动降低池的 min_size 属性从 2 降低到 1,允许每个放置组 (PG) 仅使用一个可用副本保持活动和干净。如果 min_size 保持在 2,则幸存站点无法在失去一半本地副本后维护活动 PG,从而导致客户端 I/O 冻结。通过暂时将 min_size 降低到 1,Ceph 确保集群可以容忍幸存站点中的 OSD 故障,并继续提供读/写服务,直到离线站点恢复。
重要的是要注意,暂时使用 min_size=1 意味着直到离线站点恢复,只有一份数据副本可用。虽然这可以保持服务运行,但也增加了如果幸存站点经历其他故障时数据丢失的风险。配备 SSD 介质的 Ceph 集群可确保快速恢复并最大限度地减少在 stretch 降级操作期间发生其他组件故障时数据不可用或丢失的风险。
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 11.76
pool 2 'rbdpool' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 2.62
主要 OSD 发生故障的所有 PG 都会在受影响的 OSD 被声明为 down 并且根据 Stretch 模式修改活动集后,经历客户端操作中的短暂中断。
客户端继续从幸存站点的两个副本中读取和写入数据,确保服务可用性和 RPO=0 的所有写入。
从 Stretch 降级模式恢复 ¶
当离线的数据中心恢复服务时,其 OSD 会重新加入集群,Ceph 会自动从降级 Stretch 模式恢复到完全 Stretch 模式。该过程涉及恢复和回填,以将每个放置组 (PG) 恢复到正确的副本计数 4。
当 OSD 具有有效的 PG 日志(并且只是短暂离线时),Ceph 会通过仅复制其他副本中的新更新来执行增量恢复。当 OSD 离线时间过长且 PG 日志不包含完整的增量时,Ceph 会启动 OSD 回填操作,以复制整个 PG。这会系统地扫描权威副本中的所有 RADOS 对象,并使用更改更新返回的 OSD,这些更改是在它们不可用时发生的。
恢复和回填涉及额外的 I/O,因为数据在站点之间传输以恢复完全冗余。这就是为什么在网络计算和规划中包含恢复吞吐量至关重要的原因。Ceph 旨在通过可配置的 mClock 恢复/回填设置来限制这些操作,以防止其压倒客户端 I/O。我们希望尽快返回到 HEALTH_OK,以确保数据可用性和持久性,因此足够的站点间带宽至关重要。这意味着不仅要考虑日常读写操作的带宽,还要考虑组件发生故障或集群扩展时峰值带宽。
一旦所有受影响的 PG 完成恢复或回填,它们将返回到 active+clean,每个站点都有两个最新的可用副本。然后,Ceph 会恢复在降级模式期间所做的临时更改(例如,将 min_size=1 恢复到标准的 min_size=2)。一旦完成,降级 Stretch 模式警告就会消失,表明已恢复完全冗余。
站点故障和恢复的快速演示 ¶
在此快速演示中,我们正在运行一个应用程序,该应用程序不断从 RBD 块卷读取和写入数据。蓝色和绿色的点是应用程序的读取和写入以及延迟。在仪表板的左侧和右侧,我们将显示站点的状态,并且当它们不可访问时,各个服务器将被显示为关闭。在演示中,我们可以看到我们如何失去整个站点,并且我们的应用程序仅报告 27 秒的延迟 I/O:检测并确认 OSD 处于关闭状态所需的时间。一旦站点恢复,我们就可以看到 PG 使用剩余站点上的副本进行恢复。
结论 ¶
在本期最后一篇中,我们看到了两站点 Stretch 集群对数据中心故障的反应。它会自动过渡到降级状态以保持服务在线,并在故障站点恢复时无缝恢复。凭借自动标记关闭、放宽的对等规则、降低的 min_size 值以及连接返回后同步修改的数据,Ceph 可以处理这些事件,而无需手动干预和数据丢失。
作者感谢 IBM 对社区的支持,为我们提供时间来创建这些帖子。