Ceph 对象存储多站点复制系列。第一部分
Ceph 对象存储多站点复制系列 ¶
在这一系列文章中,我们将提供动手实践的示例,帮助您设置和配置 Ceph 对象存储解决方案的一些关键复制功能。 这将包括 Reef 版本中发布的新对象存储多站点增强功能。
从宏观层面上讲,本系列将涵盖以下主题
- Ceph 对象存储多站点复制简介。
- Ceph 对象多站点架构与配置
- Reef 中的新性能改进:复制同步公平性
- 负载均衡 RGW 服务:部署 Ceph Ingress 服务
- Ceph 对象多站点同步策略
- Ceph 对象存储归档区
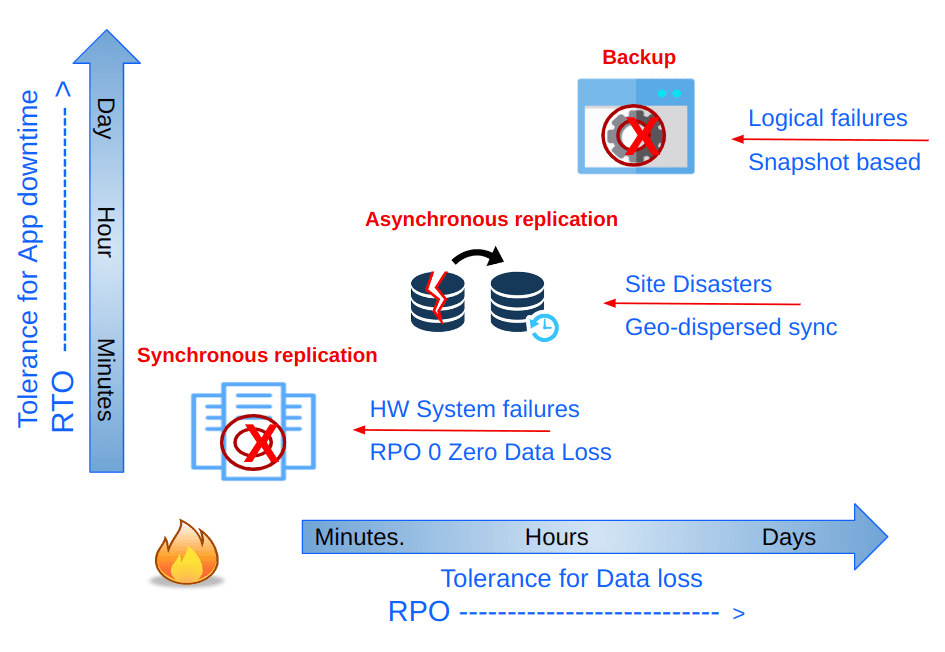
在讨论复制、灾难恢复、备份和恢复时,我们有多种策略可用,这些策略为数据和应用程序恢复提供不同的 SLA(RTO / RPO)。 例如,同步复制提供最低的 RPO,这意味着零数据丢失。 Ceph 可以通过在数据中心之间扩展 Ceph 集群来提供同步复制。 另一方面,异步复制将假定非零 RPO。 在 Ceph 中,异步多站点复制涉及将数据复制到另一个 Ceph 集群。 Ceph 的每种存储模式(对象、块和文件)都有其自身的异步复制机制。 本博客系列将涵盖地理分散的对象存储多站点异步复制。

Ceph 对象存储多站点复制简介 ¶
在开始部署细节之前,让我们快速概述一下 Ceph 对象存储 (RGW) 提供的功能:企业级、高度成熟的对象地理复制能力。 RGW 多站点复制功能促进了跨单个或多个区域部署的异步对象复制。 Ceph 对象存储使用异步复制和最终一致性,在 WAN 连接上高效运行。
Ceph 对象存储多站点复制为必须跨多个位置存储和管理大量数据的企业提供了许多好处。 以下是使用 Ceph 对象存储多站点复制的一些主要好处
改进的数据可用性,多区域 ¶
Ceph 对象存储集群可以地理分散,从而提高数据可用性并降低硬件故障、自然灾害或其他事件导致的数据丢失风险。 由于我们正在进行最终一致性的异步复制,因此没有网络延迟要求。
主动/主动复制 ¶
复制对于数据(对象)访问是主动/主动的。 多个最终用户可以同时从/向其最近的 RGW(S3)端点位置读取/写入。 换句话说,复制是双向的。 这使用户能够更快地访问数据并减少停机时间。
值得注意的是,只有区域组中的指定主区域才接受元数据更新。 例如,在创建用户和存储桶时,非主区域的所有元数据修改都将转发到配置的主区域。 如果主区域发生故障,则必须手动触发主区域故障转移。
提高可扩展性 ¶
通过多站点复制,企业可以通过添加新站点或集群来快速扩展其存储基础设施。 这使企业能够存储和管理大量数据,而无需担心存储容量或性能不足。
领域、区域组和区域 ¶
Ceph 对象存储多站点集群由领域、区域组和区域组成
领域定义了跨多个 Ceph 存储集群的全局命名空间
区域组可以有一个或多个区域
接下来是区域。 这些是 Ceph 多站点配置的最低级别,它们由单个 Ceph 集群中的一个或多个对象网关表示。
如以下图所示,Ceph 对象存储多站点复制发生在区域级别。 我们有一个名为的单个领域,以及两个区域组。 领域的全局对象命名空间确保跨区域组和区域的唯一对象 ID。
每个存储桶由创建它的区域组拥有,其对象数据仅会被复制到该区域组中的其他区域。 发送到其他区域组的该存储桶中的数据的任何请求都将被重定向到驻留存储桶的区域组。

在 Ceph 对象存储集群中,您可以有一个或多个领域。 每个领域都是一个独立的全局对象命名空间,这意味着每个领域将拥有自己的一组用户、存储桶和对象。 例如,您不能在单个领域内拥有两个名称相同的存储桶。 在 Ceph 对象存储中,还有租户的概念来隔离 S3 命名空间,但此处不讨论该问题。 您可以在此页面上找到更多信息
下图显示了一个示例,其中有两个不同的领域,因此有两个独立的命名空间。 每个领域都有其区域组和复制区域。

每个区域代表一个 Ceph 集群,并且您可以在一个区域组中拥有一个或多个区域。 配置多站点复制时,它将在区域之间发生。 在本系列博客中,我们将在一个区域组中配置两个区域,但您可以配置单个区域组中更多数量的复制区域。
Ceph 多站点复制策略 ¶
随着最新的 6.1 版本,Ceph 对象存储引入了“多站点同步策略”,该策略提供细粒度的存储桶级别复制,为用户提供更大的灵活性和降低的成本,解锁了各种有价值的复制功能
用户可以为单个存储桶启用或禁用同步,从而可以精确控制复制工作流程。
在选择退出复制特定存储桶的同时进行全区域复制
使用多个目标存储桶复制单个源存储桶
为每个存储桶实施对称和定向数据流配置
下图显示了同步策略功能在实际操作中的示例。

Ceph 多站点配置 ¶
架构概述 ¶
作为 Quincy 版本的的一部分,一个新的 Ceph Manager 模块 rgw 被添加到 ceph orchestrator cephadm 中。 rgw 管理器模块使多站点复制的配置变得简单明了。 本节将向您展示如何使用新的 rgw 管理器模块通过 CLI 在两个区域(每个区域都是一个独立的 Ceph 集群)之间配置 Ceph 对象存储多站点复制。
注意:在 Reef 及更高版本中,也可以使用 Ceph UI/Dashboard 执行多站点配置。 我们在本指南中不使用 UI,但如果您有兴趣,可以在此处找到更多信息。
在我们的设置中,我们将使用以下逻辑布局配置我们的多站点复制:我们有一个名为 multisite 的领域,该领域包含一个名为 multizg 的区域组。 在区域组内部,我们有两个区域,名为 zone1 和 zone2。 每个区域代表一个位于地理上分散的数据中心的 Ceph 集群。 以下图是我们的多站点配置的逻辑表示。

由于这是一个实验室部署,这是一个缩减的示例。 每个 Ceph 集群由四个节点组成,每个节点有六个 OSD。 我们为每个集群配置四个 RGW 服务(每个节点一个)。 两个 RGW 将服务 S3 客户端请求,其余 RGW 服务将负责多站点复制操作。 Ceph 对象存储多站点复制数据通过 RGW 服务使用 HTTP 协议传输到其他站点。 它的优点是,在网络层上,我们只需要启用/允许 Ceph 集群(区域)之间的 HTTP 通信,以便配置多站点。
下图显示了我们将逐步配置的最终架构。

在我们的示例中,我们将通过站点负载均衡器终止来自客户端的 SSL 连接。 RGW 服务将对所有涉及的端点使用纯 HTTP。
在配置 TLS/SSL 时,我们可以终止从客户端到 S3 端点的加密连接在负载均衡器级别或在 RGW 服务级别。 也可以同时进行,在负载均衡器到 RGW 重新加密连接,但 Ceph ingress 服务目前不支持此场景。
第二篇文章将列举建立我们 Ceph 集群之间多站点复制的步骤,如以下图所示。

但在开始配置 Ceph 对象存储多站点复制之前,我们需要提供更多关于我们初始状态的背景信息。 我们有两个 Ceph 集群已部署,第一个集群的节点为 ceph-node-00 到 ceph-node-03,第二个集群的节点为 ceph-node-04 到 ceph-node-07。
[root@ceph-node-00 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-node-00.cephlab.com 192.168.122.12 _admin,osd,mon,mgr
ceph-node-01.cephlab.com 192.168.122.179 osd,mon,mgr
ceph-node-02.cephlab.com 192.168.122.94 osd,mon,mgr
ceph-node-03.cephlab.com 192.168.122.180 osd
4 hosts in cluster
[root@ceph-node-04 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-node-04.cephlab.com 192.168.122.138 _admin,osd,mon,mgr
ceph-node-05.cephlab.com 192.168.122.175 osd,mon,mgr
ceph-node-06.cephlab.com 192.168.122.214 osd,mon,mgr
ceph-node-07.cephlab.com 192.168.122.164 osd
4 hosts in cluster
核心 Ceph 服务已部署,加上 Ceph 的可观察性堆栈,但没有部署 RGW 服务。 Ceph 服务正在使用 Podman 在 RHEL 上以容器化方式运行。
[root@ceph-node-00 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 6m ago 3w count:1
ceph-exporter 4/4 6m ago 3w *
crash 4/4 6m ago 3w *
grafana ?:3000 1/1 6m ago 3w count:1
mgr 3/3 6m ago 3w label:mgr
mon 3/3 6m ago 3w label:mon
node-exporter ?:9100 4/4 6m ago 3w *
osd.all-available-devices 4 6m ago 3w label:osd
prometheus ?:9095 1/1 6m ago 3w count:1
[root@ceph-node-00 ~]# ceph version
ceph version 18.2.0-131.el9cp (d2f32f94f1c60fec91b161c8a1f200fca2bb8858) reef (stable)
[root@ceph-node-00 ~]# podman inspect cp.icr.io/cp/ibm-ceph/ceph-7-rhel9 | jq .[].Labels.summary
"Provides the latest IBM Storage Ceph 7 in a fully featured and supported base image."
# cat /etc/redhat-release
Red Hat Enterprise Linux release 9.2 (Plow)
总结与下一步 ¶
作为总结,在本系列的第一部分中,我们介绍了 Ceph 对象存储多站点复制功能和架构的概述,为在本系列第二部分开始配置多站点复制奠定了基础。
脚注 ¶
作者谨此感谢 IBM 对社区的支持,通过促使我们有时间创建这些帖子。