使用 NVMe over TCP 实现规模化性能
使用 NVMe over TCP 实现规模化性能 ¶
探索 NVMe over TCP 的性能:彻底变革数据存储 ¶
在数据驱动的世界中,对更快、更高效的存储解决方案的需求正在不断增长。随着企业、云提供商和数据中心寻求处理不断增加的数据量,存储性能已成为关键因素。NVMe over TCP (NVMe/TCP,又名 NVMeoF) 是该领域最有希望的创新之一,它允许通过传统的 TCP/IP 网络部署高性能的非易失性存储器 Express (NVMe) 存储设备。本文深入探讨 Ceph 以及我们最新的块协议:NVMe over TCP 的性能、优势、挑战以及该技术的展望。我们将探索性能配置文件和填充了 NVMe SSD 的节点,以详细介绍针对高性能优化的设计。
了解 NVMe 和 TCP:快速概述 ¶
在深入研究性能细节之前,让我们先阐明所涉及的关键技术
NVMe (非易失性存储器 Express) 是一种旨在通过利用高速 PCIe (外围组件互连 Express) 总线提供对存储介质的快速数据访问的协议。NVMe 降低了延迟,提高了吞吐量,并增强了与 SATA 和 SAS 等传统存储相比的整体存储性能,同时保持了每 TB 成本最多略有增加的价格点。从性能、规模和吞吐量的角度来看,NVMe 驱动器是该领域的明确性价比之选。
TCP/IP (传输控制协议/互联网协议) 是现代网络的基础支柱之一。它是一种可靠的、面向连接的协议,可确保数据在网络上传输正确。TCP 以其鲁棒性和广泛使用而闻名,使其成为在长距离和云环境中连接 NVMe 设备的理想选择。
Ceph 将 NVMe over TCP 推向市场,提供 NVMe 速度和低延迟访问网络存储解决方案,而无需像光纤通道、InfiniBand 或 RDMA 这样的专用硬件。
NVMe over TCP 性能:期望值 ¶
NVMe over TCP 的性能在很大程度上取决于底层的网络基础设施、存储架构和设计以及所处理的工作负载。但是,有几个关键因素需要牢记
- 延迟和吞吐量:NVMe 旨在最大限度地减少延迟,这种优势延续到 NVMe over TCP。虽然 TCP 本身由于其连接管理功能(与 RDMA 等低延迟协议相比)会引入一些延迟,但 NVMe over TCP 仍然比传统的网络存储协议提供更好的延迟。值得注意的是:在规模上,延迟和吞吐量之间存在明确的权衡,如本文所示。当针对定义的架构推动性能极限时,Ceph 不会发生故障或失败,我们只是在为更高吞吐量需求提供服务时看到延迟增加。在为任何给定工作负载设计 IOPS 和延迟时,请务必记住这一点。
- 网络拥塞和丢包:TCP 以其在网络拥塞和丢包方面的可靠性而闻名,这归功于其内置的纠错和重传机制。但是,这些功能有时会引入性能瓶颈,尤其是在流量大或网络连接不可靠的环境中。例如,如果网络变得拥塞,TCP 的流量控制机制可能会限制性能以确保数据完整性。为了缓解这种情况,企业通常部署服务质量 (QoS) 和服务等级 (CoS) 机制来微调网络参数并确保平滑的数据传输。
- CPU 开销:虽然 NVMe over TCP 消除了对专用硬件的需求,但它可能会由于 TCP/IP 堆栈所需的协议处理而引入一些 CPU 开销。NVMe/TCP 需要更多的 CPU,因为存储工作负载处理发生在 CPU 上。但是,我们确实看到,随着工作负载需求的增加,消耗的 CPU 核心数量增加,从而降低了延迟并提高了吞吐量。
- 优化和调整:要从 NVMe over TCP 中获得最佳性能,网络管理员通常需要微调几个参数,包括 TCP 窗口大小、缓冲区大小和拥塞控制设置。通过 TCP 卸载和基于 TCP/UDP 的拥塞控制等优化,可以增强 NVMe over TCP 的性能,以更好地满足苛刻工作负载的需求。对于 Ceph,我们可以深入研究软件参数,这些参数在针对您的硬件平台进行调整时,可以在不增加额外成本或硬件复杂性的情况下最大限度地提高性能。
定义 ¶
让我们定义 Ceph 世界中的一些重要术语,以确保我们了解哪些参数可以推动性能和规模。
OSD (对象存储守护程序) 是 Ceph 软件定义存储系统的对象存储守护程序。它管理物理存储驱动器上的数据,并提供通过网络访问该数据的功能。对于本文而言,我们可以说 OSD 是管理给定物理设备的磁盘 IO 的软件服务。
Reactor / Reactor Core:这是软件开发中的事件处理模型,包括运行单个线程的事件循环,该线程处理 NVMe/TCP 的 IO 请求。默认情况下,我们从 4 个 reactor 核心线程开始,但此模型可以通过软件参数进行调整。
BDevs_per_cluster:BDev 是块设备的缩写,此驱动程序是 NVMe 网关与 Ceph RBD 镜像通信的方式。这很重要,因为默认情况下,NVMe/TCP 网关利用单个集群上下文中的 32 个 BDev,即每个 librbd 客户端(或连接到底层卷的存储客户端)。此可调整参数可以调整为提供 1:1 上下文的缩放,即 NVMe 卷到 librbd 客户端,从而为给定卷创建一个无争议的性能路径,但代价是更多的计算资源。
性能 ¶
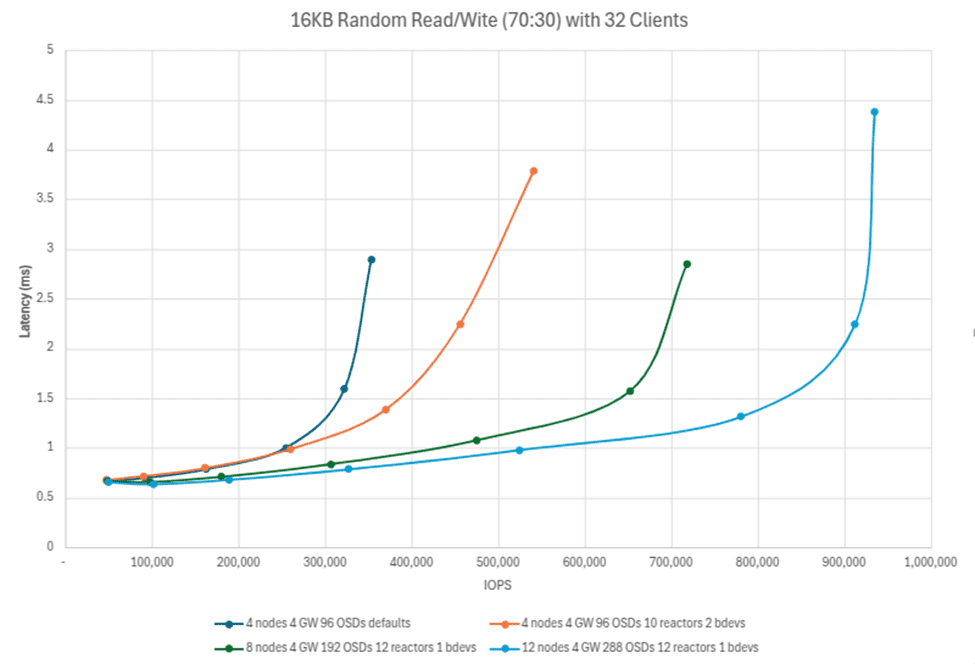
开局强劲,下面我们看到,向 Ceph 集群添加驱动器 (OSD) 和节点如何可以全面提高 IO 性能。一个具有每个节点 24 个驱动器的 4 节点 Ceph 集群,可以使用 70:30 的读/写配置文件提供超过 45 万 IOPS,使用 16k 块大小和 32 个 FIO 客户端。这相当于每个节点平均超过 10 万 IOPS!随着节点和驱动器的增加,这种趋势线性扩展,显示了一个 12 节点、288 OSD 集群的接近 100 万 IOPS 的峰值。值得注意的是,较高的数字显示了 12 个反应堆和 1 个 librbd 客户端/命名空间 (bdevs_per_cluster=1),这表明添加 librbd 客户端如何能够为服务底层 RBD 镜像及其映射的 NVMe 命名空间的 OSD 提供更多吞吐量。

下面的测试显示了如何调整环境以适应底层硬件,从而可以在软件定义存储中实现巨大的改进。我们从一个简单的 4 节点集群开始,并显示了 16、32、64 和 96 个 OSD 的缩放点。在此测试中,Ceph 对象存储守护程序已 1:1 映射到物理 NVMe 驱动器。
仅仅添加驱动器和节点似乎只能获得适度的性能提升,但对于软件定义存储,始终需要在服务器利用率和存储性能之间进行权衡——在这种情况下,权衡是有利的。当相同的集群将默认反应堆核心从 4 增加到 10(从而消耗更多的 CPU 周期),并且配置 ``bdevs_per_cluster` 以通过添加 librbd 客户端增加软件吞吐量时,性能几乎翻倍。仅仅通过将环境调整到底层硬件并使 Ceph 利用这种处理能力即可实现所有这些。

下面的图表显示了在三个“T 恤尺寸”的调整后的 4 节点、8 节点和 12 节点配置中提供的 IOPS,以及启用默认设置的 4 节点集群进行比较。再次,我们可以看到,对于 <2ms 延迟工作负载,Ceph 线性且以可预测的方式扩展。注意:随着 I/O 变得拥塞,在某个点,工作负载仍然可用,但响应时间延迟更高。Ceph 继续提交所需的读取和写入,仅在现有平台设计边界饱和时才会达到平台。

NVMe over TCP 的未来 ¶
随着存储需求不断发展,NVMe over TCP 将成为高性能存储领域中的关键角色。随着以太网速度、TCP 优化和网络基础设施的不断进步,NVMe over TCP 将继续为广泛的应用提供引人注目的优势,从企业数据中心到边缘计算环境。
Ceph 将成为 NVMe over TCP 软件定义存储的顶级执行者,不仅能够实现高性能、可扩展的 NVMe 存储平台,而且能够通过用户控制的软件增强和配置实现平台上的更多性能。
结论 ¶
Ceph 的 NVMe over TCP 目标提供了一种强大、可扩展且具有成本效益的解决方案,用于高性能存储网络。
作者谨向 IBM 致谢,感谢他们通过我们的时间来创建这些帖子来支持社区。