使用 S3 Bucket Logging API 增强面向最终用户的对象存储日志记录
使用 S3 Bucket Logging API 增强面向最终用户的对象存储日志记录 ¶
介绍 Ceph S3 Bucket Logging ¶
Squid 19.2.2 中引入的新 S3 bucket logging 功能使跟踪、监控和保护 bucket 操作比以往任何时候都更加简单。它与 S3 自助服务用例保持一致,允许最终用户通过熟悉的 S3 API 配置和管理他们的应用程序存储访问日志。这种功能使他们能够监控访问模式、检测未经授权的活动并分析使用趋势,而无需管理员的直接干预。
通过利用 Ceph 的日志记录功能,用户可以通过存储在专用 bucket 中的日志获得可操作的见解,从而在跟踪操作方面提供灵活性和粒度。
重要的是要注意,此功能并非旨在提供实时性能指标和监控:我们有 Ceph 提供的可观察性堆栈来满足这些需求。
在 AWS 中,Ceph 的 Bucket Logging S3 API 的等效项是指 S3 服务器访问日志。
在本博客中,我们将为我们的应用程序构建一个示例交互式 Superset 仪表板,该仪表板使用启用 S3 bucket logging 时生成的日志数据。

S3 Bucket Logging 的示例用例 ¶
应用程序合规性和审计
受监管行业(金融、医疗保健、保险等)中的应用程序团队必须维护详细的访问日志,以满足合规性要求并确保数据操作的可追溯性。安全性和入侵检测
监控 bucket 访问模式以识别未经授权的活动、检测异常情况并响应潜在的安全漏洞。每个应用程序的使用分析
生成有关 bucket 的详细见解,包括哪些对象经常被访问、高峰流量时间以及操作模式。最终用户成本优化
跟踪资源使用情况,例如GET、PUT和DELETE请求的数量,以优化存储和运营成本。最终用户自助监控
在 S3 即服务的自助设置中,最终用户可以配置日志记录以获取其活动的历史视图,帮助他们管理数据并在无需管理员干预的情况下检测问题。增量备份的更改跟踪(特定于 Journal 模式)
在启用 journal 模式的情况下,bucket 中的所有更改都会在操作完成之前记录到日志中,从而创建一个可靠的更改日志。备份应用程序可以使用此日志来盘点更改以执行高效的增量备份。以下是 Yuval Lifshitz 的一个示例 Rclone PR,它使用 bucket logging 功能来允许更高效的增量复制自 S3。
日志记录模式:标准与 Journal ¶
标准(默认) ¶
日志记录写入日志 bucket 的时间是在操作完成后。如果日志记录操作失败,则会静默失败,不会通知客户端。
Journal ¶
日志记录写入日志 bucket 的时间是在操作完成之前。如果日志记录失败,则操作将停止,并向客户端返回错误。对于多删除和删除操作,即使日志记录失败,操作也可能成功。请注意,日志可能反映成功的写入,即使操作失败。
动手实践:配置 Bucket Logging ¶
作为上下文,我有一个 Ceph 对象网关 (RGW) 服务在 Squid 集群上运行。
# ceph version
ceph version 19.2.0-53.el9cp (677d8728b1c91c14d54eedf276ac61de636606f8) squid (stable)
# ceph orch ls rgw
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
rgw.default ?:8000 4/4 6m ago 8M ceph04;ceph03;ceph02;ceph06;count:4
我有一个名为 analytic_ap 的 IAM 帐户,以及一个名为 rootana 的 root 用户:S3 用户的配置文件 rootana 已经通过 AWS CLI 配置。
通过 RGW 端点使用 IAM API(无需 RGW 管理员干预),我将创建一个新用户,并附加一个名为 AmazonS3FullAccess 的托管策略,以便该用户可以访问 analytic_ap 帐户中的所有 bucket。
# aws --profile rootana iam create-user --user-name app_admin_shooters
{
"User": {
"Path": "/",
"UserName": "app_admin_shooters",
"UserId": "d915f592-6cbc-4c4c-adf2-900c499e8a4a",
"Arn": "arn:aws:iam::RGW46950437120753278:user/app_admin_shooters",
"CreateDate": "2025-01-23T08:26:44.086883+00:00"
}
}
# aws --profile rootana iam create-access-key --user-name app_admin_shooters
{
"AccessKey": {
"UserName": "app_admin_shooters",
"AccessKeyId": "YI80WC6HTMHMY958G3EO",
"Status": "Active",
"SecretAccessKey": "67Vp071aBf92fJiEe8pBtV6RYqtWBhSceneeZVLH",
"CreateDate": "2025-01-23T08:27:03.268781+00:00"
}
}
# aws --profile rootana iam attach-user-policy --user-name app_admin_shooters --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess
我通过 AWS CLI 配置了一个新配置文件,其中包含我们刚刚创建的 S3 最终用户的凭据,名为 app_admin_shooters,附加到用户的托管策略使我能够访问帐户中可用的 S3 资源
# aws --profile app_admin_shooters s3 ls
#
好的,一切准备就绪,让我们创建三个源 bucket。这些 bucket 属于三个不同的射击游戏/应用程序,还有一个名为 shooterlogs 的日志目标 bucket
# aws --profile app_admin_shooters s3 mb s3://shooterlogs
make_bucket: shooterlogs
# aws --profile app_admin_shooters s3 mb s3://shooterapp1
make_bucket: shooterapp1
]# aws --profile app_admin_shooters s3 mb s3://shooterapp2
make_bucket: shooterapp2
# aws --profile app_admin_shooters s3 mb s3://shooterapp3
make_bucket: shooterapp3
现在让我们为我的每个射击应用程序 bucket 启用 bucket logging。我将使用目标 bucket shooter logs,为了组织每个 shooterapp bucket 的日志,我将使用名称为 bucket 名称的 TargetPprefix
# cat << EOF > enable_logging.json
{
"LoggingEnabled": {
"TargetBucket": "shooterlogs",
"TargetPrefix": "shooterapp1"
}
}
EOF
准备好 JSON 文件后,我们可以使用 sed 命令在每次迭代中更改 TargetPrefix 来将其应用于我们的 bucket。
# aws --profile app_admin_shooters s3api put-bucket-logging --bucket shooterapp1 --bucket-logging-status file://enable_logging.json
# sed -i 's/shooterapp1/shooterapp2/' enable_logging.json
# aws --profile app_admin_shooters s3api put-bucket-logging --bucket shooterapp2 --bucket-logging-status file://enable_logging.json
# sed -i 's/shooterapp2/shooterapp3/' enable_logging.json
# aws --profile app_admin_shooters s3api put-bucket-logging --bucket shooterapp3 --bucket-logging-status file://enable_logging.json
我们可以使用以下 s3api 命令列出 bucket 的日志记录配置。
# aws --profile app_admin_shooters s3api get-bucket-logging --bucket shooterapp1
{
"LoggingEnabled": {
"TargetBucket": "shooterlogs",
"TargetPrefix": "shooterapp1",
"TargetObjectKeyFormat": {
"SimplePrefix": {}
}
}
}
我们将 PUT 一些对象到我们的第一个 bucket shooterapp1 中,并删除一组对象,以便在我们的日志 bucket 中创建日志。
# for i in {1..20} ; do aws --profile app_admin_shooters s3 cp /etc/hosts s3://shooterapp1/file${i} ; done
upload: ../etc/hosts to s3://shooterapp1/file1
upload: ../etc/hosts to s3://shooterapp1/file2
…
# for i in {1..5} ; do aws --profile app_admin_shooters s3 rm s3://shooterapp1/file${i} ; done
delete: s3://shooterapp1/file1
delete: s3://shooterapp1/file2
…
当我们检查我们配置的日志 bucket shooterlogs 时,它是空的。为什么!?
# aws --profile app_admin_shooters s3 ls s3://shooterlogs/
#
来自文档的说明:为了提高性能,即使日志记录写入持久存储,日志对象也会在经过可配置的时间量(或达到最大对象大小 128MB)后才会出现在日志 bucket 中。此时间(以秒为单位)可以通过 Ceph 扩展到 REST API,为每个源 bucket 设置,也可以通过 rgw_bucket_logging_obj_roll_time 配置选项全局设置。如果未设置,则默认时间为 5 分钟。将日志对象添加到日志 bucket 是“延迟”完成的,这意味着如果没有更多记录写入对象,即使在配置的时间过去之后,它也可能仍然在日志 bucket 之外。
如果我们不想等待对象滚动时间(默认为 5 分钟),可以使用 radosgw-admin 命令强制刷新日志缓冲区
# radosgw-admin bucket logging flush --bucket shooterapp1
再次检查时,包含 bucket shooterapp1 日志的对象如预期的那样存在
# aws --profile app_admin_shooters s3 ls s3://shooterlogs/
2025-01-23 08:28:16 8058 shooterapp12025-01-23-13-21-00-A54CQC9GIO7O4F9D
# aws --profile app_admin_shooters s3 cp s3://shooterlogs/shooterapp12025-01-23-13-21-00-A54CQC9GIO7O4F9D - | cat
RGW46950437120753278 shooterapp1 [23/Jan/2025:13:21:00 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323278.12172315742054314872 REST.GET.get_bucket_logging - "GET /shooterapp1?logging HTTP/1.1" 200 - - - - 14ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
RGW46950437120753278 shooterapp1 [23/Jan/2025:13:23:33 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323242.15617167555539888584 REST.PUT.put_obj file1 "PUT /shooterapp1/file1 HTTP/1.1" 200 - 333 333 - 19ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
…
RGW46950437120753278 shooterapp1 [23/Jan/2025:13:24:01 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323242.18353336346755391699 REST.DELETE.delete_obj file1 "DELETE /shooterapp1/file1 HTTP/1.1" 204 NoContent - 333 - 11ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
RGW46950437120753278 shooterapp1 [23/Jan/2025:13:24:02 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.311105.12134465030800156375 REST.DELETE.delete_obj file2 "DELETE /shooterapp1/file2 HTTP/1.1" 204 NoContent - 333 - 11ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
RGW46950437120753278 shooterapp1 [23/Jan/2025:13:24:03 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323260.3289411001891924009 REST.DELETE.delete_obj file3 "DELETE /shooterapp1/file3 HTTP/1.1" 204 NoContent - 333 - 9ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com -
注意:要探索当前 bucket logging 功能可用的输出字段,请查看 文档。
让我们看看 bucket logging 是否适用于我们的另一个 bucket shooterapp2。
# for i in {1..3} ; do aws --profile app_admin_shooters s3 cp /etc/hosts s3://shooterapp2/file${i} ; done
upload: ../etc/hosts to s3://shooterapp2/file1
upload: ../etc/hosts to s3://shooterapp2/file2
upload: ../etc/hosts to s3://shooterapp2/file3
# for i in {1..3} ; do aws --profile app_admin_shooters s3 cp s3://shooterapp2/file${i} - ; done
# radosgw-admin bucket logging flush --bucket shooterapp2
flushed pending logging object 'shooterapp22025-01-23-10-01-57-TJNTA3FU60TS21MK' to target bucket 'shooterlogs'
检查我们配置的日志 bucket,我们可以看到我们现在有两个对象在 bucket 中,其前缀是源 bucket 名称。
# aws --profile app_admin_shooters s3 ls s3://shooterlogs/
2025-01-23 08:28:16 8058 shooterapp12025-01-23-13-21-00-A54CQC9GIO7O4F9D
2025-01-23 10:01:57 2628 shooterapp22025-01-23-15-00-48-FIE6B8NNMANFTTFI
# aws --profile app_admin_shooters s3 cp s3://shooterlogs/shooterapp22025-01-23-15-00-48-FIE6B8NNMANFTTFI - | cat
RGW46950437120753278 shooterapp2 [23/Jan/2025:15:00:48 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323242.10550516265852869740 REST.PUT.put_obj file1 "PUT /shooterapp2/file1 HTTP/1.1" 200 - 333 333 - 22ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
RGW46950437120753278 shooterapp2 [23/Jan/2025:15:00:49 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a
…
RGW46950437120753278 shooterapp2 [23/Jan/2025:15:01:36 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323278.16364063589570559207 REST.HEAD.get_obj file1 "HEAD /shooterapp2/file1 HTTP/1.1" 200 - - 333 - 4ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
RGW46950437120753278 shooterapp2 [23/Jan/2025:15:01:36 +0000] - d915f592-6cbc-4c4c-adf2-900c499e8a4a fcabdf4a-86f2-452f-a13f-e0902685c655.323242.2016501269767674837 REST.GET.get_obj file1 "GET /shooterapp2/file1 HTTP/1.1" 200 - - 333 - 3ms - - - - - - - s3.cephlabs.com.s3.cephlabs.com - -
使用 Trino 和 Superset 解锁见解:可视化您的应用程序日志 ¶

配置 Trino 以在我们的应用程序日志中运行 SQL 查询。¶
在本指南中,我们将引导您设置 Trino 以查询存储在 S3 兼容存储中的应用程序日志,并探索您可以使用的一些强大的 SQL 查询来分析数据。
我们已经有正在运行的 Trino;我已配置 hive 连接器以使用 S3A 访问我们的 S3 端点,有关如何设置 Trino 的说明。
第一步是配置一个外部表,指向存储在 S3 兼容 bucket 中的日志数据:在我们的示例中,shooterlogs。以下是创建表的示例
trino> SHOW CREATE TABLE hive.default.raw_logs;
Create Table
----------------------------------------------
CREATE TABLE hive.default.raw_logs (
line varchar
)
WITH (
external_location = 's3a://shooterlogs/',
format = 'TEXTFILE'
)
为了使数据更易于使用,您可以将每条日志行解析为有意义的字段,包括帐户 ID、bucket 名称、操作类型、HTTP 响应代码等。为了简化查询和重用,我将创建一个封装日志解析逻辑的视图
trino> CREATE VIEW hive.default.log_summary AS
-> SELECT
-> split(line, ' ')[1] AS account_id, -- Account ID
-> split(line, ' ')[2] AS bucket_name, -- Bucket Name
-> split(line, ' ')[3] AS timestamp, -- Timestamp
-> split(line, ' ')[6] AS user_id, -- User ID
-> split(line, ' ')[8] AS operation_type, -- Operation Type
-> split(line, ' ')[9] AS object_key, -- Object Key
-> regexp_extract(line, '"([^"]+)"', 1) AS raw_http_request, -- Raw HTTP Request
-> CAST(regexp_extract(line, '"[^"]+" ([0-9]+) ', 1) AS INT) AS http_status, -- HTTP Status
-> CAST(CASE WHEN split(line, ' ')[14] = '-' THEN NULL ELSE split(line, ' ')[14] END AS BIGINT) AS object_size, -- Object Size
-> CASE WHEN split(line, ' ')[17] = '-' THEN NULL ELSE split(line, ' ')[17] END AS request_duration, -- Request Duration
-> regexp_extract(line, '[0-9]+ms', 0) AS request_time, -- Request Time (e.g., 22ms)
-> regexp_extract(line, ' ([^ ]+) [^ ]+ [^ ]+$', 1) AS hostname -- Hostname (third-to-last field)
-> FROM hive.default.raw_logs;
->
CREATE VIEW
有了视图,您可以快速编写查询来汇总日志数据。例如
trino> SELECT operation_type, COUNT(*) AS operation_count
-> FROM hive.default.log_summary
-> GROUP BY operation_type;
operation_type | operation_count
-----------------------------+-----------------
REST.DELETE.delete_obj | 5
REST.HEAD.get_obj | 3
REST.GET.get_bucket_logging | 1
REST.PUT.put_obj | 23
REST.GET.list_bucket | 1
REST.GET.get_obj | 3
(6 rows)
使用我们的应用程序日志创建有意义的图表 ¶
使用从您的 Trino 数据创建的视图,您可以执行历史监控并有效地分析您的 S3 bucket 活动。以下是一些您可以创建的潜在可视化示例,以提供有关 bucket 使用情况和访问模式的可操作见解。
- 按操作类型划分的请求量
- 按操作划分的数据传输量
- 按操作划分的平均请求持续时间
- 按用户/帐户划分的访问次数最多的对象
- 按一天中的时间划分的请求模式
- 失败的请求按操作划分
- 按 bucket/用户划分的访问模式
我将在此示例中使用 Superset,但另一个可视化工具可以实现相同的结果。我有一个正在运行的 Superset 实例,并且我已经将 Trino 配置为 Superset 的数据源。
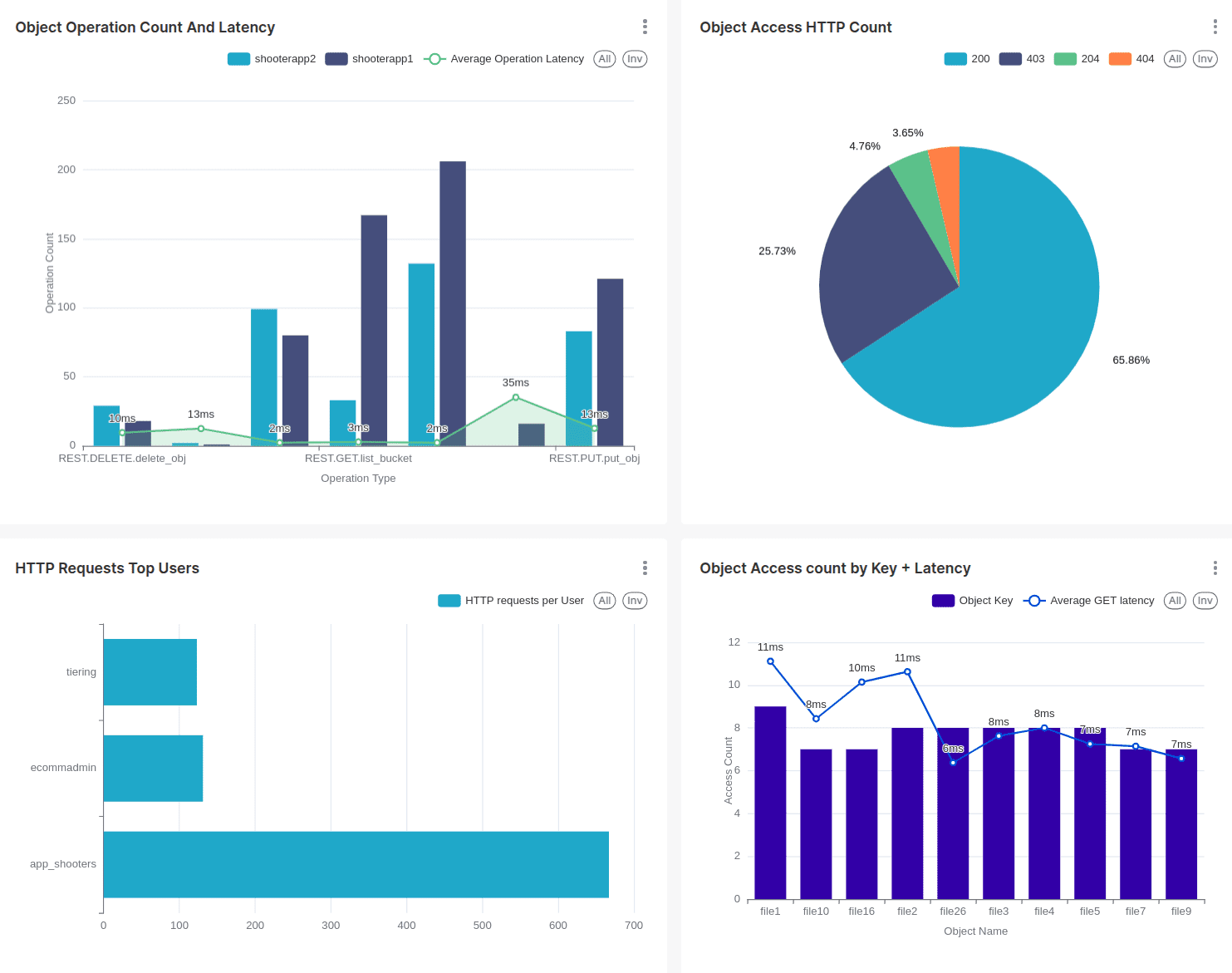
这是用于 Superset 仪表板的查询和生成的图表。我们展示了每个 bucket 的操作类型计数和平均延迟。
SELECT operation_type AS operation_type, bucket_name AS bucket_name, sum("Operations Count") AS "SUM(Operations Count)"
FROM (SELECT
bucket_name,
operation_type,
COUNT(*) AS "Operations Count",
AVG(CAST(regexp_extract(request_time, '[0-9]+', 0) AS DOUBLE)) AS "Average Latency"
FROM hive.default.log_summary
GROUP BY bucket_name, operation_type
ORDER BY "Operations Count" DESC
) AS virtual_table GROUP BY operation_type, bucket_name ORDER BY "SUM(Operations Count)" DESC
LIMIT 1000;

另一个与 HTTP 请求相关的示例是在饼图中使用 HTTP 请求代码的分布。

这里我们展示了向 shooter 应用程序 bucket 发出请求的顶级用户。

这些只是您可以创建的一些基本图表示例。可以使用 Superset 中提供的功能构建更多高级图表。
结论 ¶
S3 bucket logging 功能的引入是存储访问管理领域的变革。此功能通过使最终用户能够配置和管理他们的应用程序访问日志来提供透明度和控制。通过能够在 bucket 级别记录操作,用户可以监控活动、解决问题并增强其安全态势——所有这些都针对他们的特定要求量身定制,无需管理员干预。
为了展示其潜力,我们探讨了 Trino 和 Superset 等工具如何分析和可视化 S3 Bucket Logging 生成的日志数据。这些只是 bucket logging 功能提供的众多可能性中的几个示例。
Ceph 开发人员正在努力改进未来版本的 bucket logging,包括错误修复、增强功能和更好的 AWS S3 兼容性。敬请期待!
作者感谢 IBM 通过我们的时间来创建这些帖子来支持社区。