Ceph Crimson OSD CPU 核心分配性能调查。第一部分
Crimson:新的 OSD 高性能架构 ¶
Crimson 是新 OSD 高性能架构的项目名称。Crimson 构建于 Seastar 框架 之上,这是一个先进的、开源的 C++ 框架,用于现代硬件上的高性能服务器应用程序。Seastar 在无共享架构中实现 I/O 反应堆,使用异步计算原语,如 future、promise 和协程。I/O 反应堆线程通常固定到系统中的特定 CPU 核心。但是,为了支持与传统软件(即非反应堆阻塞任务)的交互,Seastar 中提供了 Alien 线程机制。这些允许非反应堆和 I/O 反应堆架构之间的接口。在 Crimson 中,Alien 线程用于支持 Bluestore。
社区中有很多关于该项目的优秀介绍,特别是请查看 Sam Just 和 Matan Breizman 在 Ceph 社区 Youtube 频道上的视频。
从性能角度来看,一个重要的问题是将 Seastar 反应堆线程分配给可用的 CPU 核心。这在现代 NUMA(非统一内存访问)架构中尤其重要,在 NUMA 架构中,访问不同 CPU 插槽的内存会产生延迟惩罚,而访问与运行线程相同的 CPU 插槽上的本地内存则不会。我们还希望确保反应堆和其他非反应堆线程在同一 CPU 核心内的互斥。主要原因是 Seastar 反应堆线程是非阻塞的,而非反应堆线程允许阻塞。
作为 此 PR 的一部分,我们在 vstart.sh 脚本中引入了一个新的选项,用于设置 OSD 线程的 CPU 分配策略
- 基于 OSD:这包括将相同的 NUMA 插槽中的 CPU 核心分配给相同的 OSD。为了简单起见,如果 OSD ID 是偶数,则其所有反应堆线程都分配给 NUMA 插槽 0,因此如果 OSD ID 是奇数,则其所有反应堆线程都分配给 NUMA 插槽 1。下图说明了这种策略(“R”代表“反应堆”线程,数字 ID 对应于 OSD ID)

- 基于 NUMA 插槽:这包括将每个 NUMA 插槽的 CPU 核心均匀地分配给反应堆,因此所有 OSD 最终都将反应堆分配到两个 NUMA 插槽上。

默认情况下,如果未提供该选项,vstart 将按以下顺序分配反应堆线程

值得一提的是,vstart.sh 脚本仅在开发模式下使用,这对于实验非常有用,就像在本例中一样。
此博客条目的结构如下
首先,我们简要描述了我们执行的硬件和性能测试,并附带一些片段。熟悉 Ceph 的读者可能想跳过此部分。
在第二部分中,我们展示了性能测试的结果,比较了三种 CPU 分配策略。我们使用了 Crimson 支持的三种后端类,分别是
Cyanstore:这是一个纯内存的纯反应堆 OSD 类,它不会使用系统中的物理驱动器。使用此 OSD 类的原因是使机器中的内存访问速率饱和,以识别 Crimson 在没有物理驱动器干扰(即延迟)的情况下可能实现的最高 I/O 速率。
Seastore:这也是一个纯反应堆 OSD 类,它使用机器中的物理 NVMe 驱动器。我们预计该类的整体性能将是 Cyanstore 实现性能的一小部分。
Bluestore:这是 Crimson 的默认 OSD 类,也是 Ceph 中的经典 OSD。该类涉及 Alien 线程的参与,这是 Seastore 中处理阻塞线程池的技术。
比较结果很有趣,它们突出了性能优化的局限性和机会。
性能测试计划 ¶
简而言之,我们希望使用一些典型的客户端工作负载(随机 4K 写入、随机 4K 读取;顺序 64K 写入、顺序 64K 读取)来测量性能,用于涉及固定数量的 OSD 并涵盖一定数量的 I/O 反应堆(这隐式地涵盖了相应的 CPU 核心数量)的集群配置。我们希望比较现有的对象存储:Cyanstore(内存中)、Seastore 和 Bluestore。前两者是“纯反应堆”,而后者涉及(阻塞)Alien 线程池。
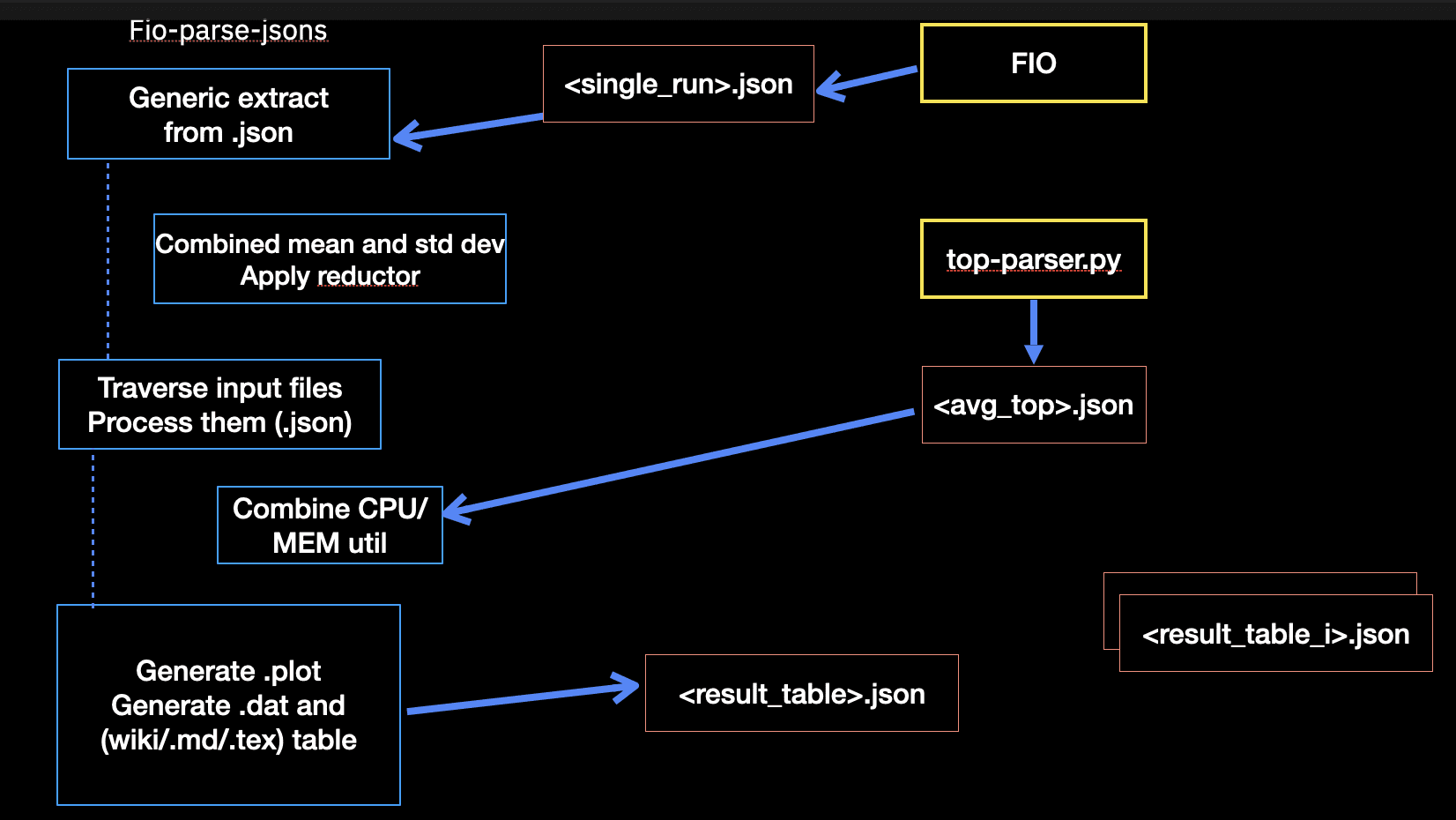
在客户端方面,我们使用 FIO 进行上述典型工作负载,使用 10 GiB 大小的 RBD 卷。我们从 FIO .json 输出(I/O 吞吐量和延迟)合成客户端结果,并将其与来自 OSD 进程的测量结果集成。这些通常涉及 CPU 和内存利用率(来自 Linux 命令 top)。此工作流程在下图所示。

在我们的实际实验中,我们涵盖了多个 OSD(1、3、5、8)以及多个反应堆(1、2、4、6)。由于结果数量会非常大,并且会使阅读此博客变得非常繁琐,因此我们决定仅显示具有代表性的 8 个 OSD 和 5 个 I/O 反应堆。
我们使用单节点集群,硬件和系统配置如下
- CPU:2 x Intel(R) Xeon(R) Platinum 8276M CPU @ 2.20GH (每个 56 个核心)
- 内存:394 GiB
- 驱动器:8 x 93.1 TB NVMe
- OS:Centos 9.0 on kernel 5.14.0-511.el9.x86_64
- Ceph:版本 b2a220 (bb2a2208867d7bce58b9697570c83d995a1c5976) squid (dev)
- podman 版本 5.2.2。
我们使用以下选项构建 Ceph
# ./do_cmake.sh -DWITH_SEASTAR=ON -DCMAKE_BUILD_TYPE=RelWithDebInfo
总的来说,我们按以下方式启动性能测试
/root/bin/run_balanced_crimson.sh -t cyan
这将为 Cyanstore 对象后端运行测试计划,生成三种 CPU 分配策略的响应曲线数据。-t 参数用于指定对象存储后端:cyan、sea 和 blue 分别用于 Cyanstore、Seastore 和 Bluestore。
crimson_be_table["cyan"]="--cyanstore"
crimson_be_table["sea"]="--seastore --seastore-devs ${STORE_DEVS}"
crimson_be_table["blue"]="--bluestore --bluestore-devs ${STORE_DEVS}"
执行完成后,结果将存档在 .zip 文件中,根据工作负载进行归档并保存在输出目录中,该目录可以使用选项 -d(默认情况下为 /tmp)指定。
点击查看生成结果的快照。
cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread.zip cyan_8osd_5reactor_8fio_bal_socket_rc_1procs_seqread.zip cyan_8osd_6reactor_8fio_bal_osd_rc_1procs_randread.zip cyan_8osd_6reactor_8fio_bal_socket_rc_1procs_seqread.zip
cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randwrite.zip cyan_8osd_5reactor_8fio_bal_socket_rc_1procs_seqwrite.zip cyan_8osd_6reactor_8fio_bal_osd_rc_1procs_randwrite.zip cyan_8osd_6reactor_8fio_bal_socket_rc_1procs_seqwrite.zip
cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_seqread.zip
每个存档包含结果输出文件和该工作负载执行的测量结果。
点击查看结果 .zip 文件内部。
最重要的文件是cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread.json:(组合) FIO 输出文件,其中包含 I/O 吞吐量和延迟测量结果。它还包含来自 OSD 进程的 CPU 和内存利用率。cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_cpu_avg.json:OSD 和 FIO CPU 和内存利用率平均值。这些已从 OSD 进程和 FIO 客户端进程通过 top 收集(在 5 分钟内采样 30 次)。cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_diskstat.json:diskstat 输出。在测试之前和之后拍摄一个样本,.json 包含差异。cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top.json:来自 top 的输出,通过 jc 解析以生成 .json。注意:jc 尚未支持单个 CPU 核心利用率,因此我们必须依赖整体 CPU 利用率(每个线程)。new_cluster_dump.json:来自ceph tell ${osd_i} dump_metrics命令的输出,其中包含单个 OSD 性能指标。FIO_cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top_cpu.plot:从 top 输出机械生成的情节,显示 FIO 客户端的 CPU 利用率随时间的变化。OSD_cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top_mem.plot:从 top 输出机械生成的情节,显示 OSD 进程的内存利用率随时间的变化。
为了进行后处理和并排比较,将运行以下脚本
# /root/bin/pp_balanced_cpu_cmp.sh -d /tmp/_seastore_8osd_5_6_reactor_8fio_rc_cmp \
-t sea -o seastore_8osd_5vs6_reactor_8fio_cpu_cmp.md
参数是:包含我们想要比较的运行的输入目录、对象存储后端类型以及要生成的输出 .md 文件。
我们将在下一部分中展示生成的比较结果。
在本节结束时,我们将深入了解上述脚本的幕后情况,展示预调驱动器、创建集群、执行 FIO 和收集的指标的详细信息。
预调驱动器 ¶
为了确保驱动器处于一致的状态,我们使用 FIO 运行一个写入工作负载,并使用 steadystate 选项。此选项可确保在运行实际性能测试之前,驱动器处于稳定状态。我们预调至驱动器总容量的 70%。
点击查看命令。
我们在测试之前和之后测量 diskstats,并使用 diskstat_diff.py 脚本计算差异。该脚本可在 ceph 仓库的 src/tools/contrib 下找到。
# jc --pretty /proc/diskstats > /tmp/blue_8osd_6reactor_192at_8fio_socket_cond.json
# fio rbd_fio_examples/randwrite64k.fio && jc --pretty /proc/diskstats \
| python3 diskstat_diff.py -d /tmp/ -a blue_8osd_6reactor_192at_8fio_socket_cond.json
Jobs: 8 (f=8): [w(8)][30.5%][w=24.3GiB/s][w=398k IOPS][eta 13m:41s]
nvme0n1p2: (groupid=0, jobs=8): err= 0: pid=375444: Fri Jan 31 11:43:35 2025
write: IOPS=397k, BW=24.2GiB/s (26.0GB/s)(8742GiB/360796msec); 0 zone resets
slat (nsec): min=1543, max=823010, avg=5969.62, stdev=2226.84
clat (usec): min=57, max=50322, avg=5152.50, stdev=2982.28
lat (usec): min=70, max=50328, avg=5158.47, stdev=2982.27
clat percentiles (usec):
| 1.00th=[ 281], 5.00th=[ 594], 10.00th=[ 1037], 20.00th=[ 2008],
| 30.00th=[ 3032], 40.00th=[ 4080], 50.00th=[ 5145], 60.00th=[ 6194],
| 70.00th=[ 7242], 80.00th=[ 8291], 90.00th=[ 9241], 95.00th=[ 9634],
| 99.00th=[10028], 99.50th=[10421], 99.90th=[14091], 99.95th=[16188],
| 99.99th=[19268]
bw ( MiB/s): min=15227, max=24971, per=100.00%, avg=24845.68, stdev=88.47, samples=5768
iops : min=243638, max=399547, avg=397527.12, stdev=1415.43, samples=5768
lat (usec) : 100=0.01%, 250=0.61%, 500=3.18%, 750=2.90%, 1000=2.88%
lat (msec) : 2=10.28%, 4=19.25%, 10=59.90%, 20=1.00%, 50=0.01%
lat (msec) : 100=0.01%
cpu : usr=19.80%, sys=15.60%, ctx=104026691, majf=0, minf=2647
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued rwts: total=0,143224767,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=256
steadystate : attained=yes, bw=24.3GiB/s (25.5GB/s), iops=398k, iops mean dev=1.215%
Run status group 0 (all jobs):
WRITE: bw=24.2GiB/s (26.0GB/s), 24.2GiB/s-24.2GiB/s (26.0GB/s-26.0GB/s), io=8742GiB (9386GB), run=360796-360796msec
创建集群 ¶
我们使用 vstart.sh 脚本创建集群,并为 Crimson 提供适当的选项。
点击查看集群创建的片段。
我们有一个 CPU 分配策略表# CPU allocation strategies
declare -A bal_ops_table
bal_ops_table["default"]=""
bal_ops_table["bal_osd"]=" --crimson-balance-cpu osd"
bal_ops_table["bal_socket"]="--crimson-balance-cpu socket"
我们基本上遍历 CPU 策略的顺序,对于 Crimson 的每个后端。在片段中,我们迭代 OSD 数量和反应堆数量,并使用新选项设置 CPU 分配策略。
重要提示:请注意,我们使用 VSTART_CPU_CORES 变量设置分配给 vstart 的 CPU 核心列表。我们使用它来确保“保留”一些 CPU 用于 FIO 客户端(因为我们使用的是单节点集群)。
# Run balanced vs default CPU core/reactor distribution in Crimson using either Cyan, Seastore or Bluestore
fun_run_bal_vs_default_tests() {
local OSD_TYPE=$1
local NUM_ALIEN_THREADS=7 # default
local title=""
for KEY in default bal_osd bal_socket; do
for NUM_OSD in 8; do
for NUM_REACTORS in 5 6; do
title="(${OSD_TYPE}) $NUM_OSD OSD crimson, $NUM_REACTORS reactor, fixed FIO 8 cores, response latency "
cmd="MDS=0 MON=1 OSD=${NUM_OSD} MGR=1 taskset -ac '${VSTART_CPU_CORES}' /ceph/src/vstart.sh \
--new -x --localhost --without-dashboard\
--redirect-output ${crimson_be_table[${OSD_TYPE}]} --crimson --crimson-smp ${NUM_REACTORS}\
--no-restart ${bal_ops_table[${KEY}]}"
# Alien setup for Bluestore, see below.
test_name="${OSD_TYPE}_${NUM_OSD}osd_${NUM_REACTORS}reactor_8fio_${KEY}_rc"
echo "${cmd}" | tee >> ${RUN_DIR}/${test_name}_cpu_distro.log
echo $test_name
eval "$cmd" >> ${RUN_DIR}/${test_name}_cpu_distro.log
echo "Sleeping for 20 secs..."
sleep 20
fun_show_grid $test_name
fun_run_fio $test_name
/ceph/src/stop.sh --crimson
sleep 60
done
done
done
}
对于 Bluestore,我们有一种特殊情况,我们将 Alien 线程的数量设置为后端 CPU 核心数量的 4 倍(crimson-smp)。
if [ "$OSD_TYPE" == "blue" ]; then
NUM_ALIEN_THREADS=$(( 4 *NUM_OSD * NUM_REACTORS ))
title="${title} alien_num_threads=${NUM_ALIEN_THREADS}"
cmd="${cmd} --crimson-alien-num-threads $NUM_ALIEN_THREADS"
test_name="${OSD_TYPE}_${NUM_OSD}osd_${NUM_REACTORS}reactor_${NUM_ALIEN_THREADS}at_8fio_${KEY}_rc"
fi
集群在线后,我们创建池和 RBD 卷。
点击查看池创建。
我们首先测量集群的一些指标,然后创建单个 RBD 池和卷(如果适用)。我们还显示集群、池和 PG 的状态。
# Take some measurements
if pgrep crimson; then
bin/ceph daemon -c /ceph/build/ceph.conf osd.0 dump_metrics > /tmp/new_cluster_dump.json
else
bin/ceph daemon -c /ceph/build/ceph.conf osd.0 perf dump > /tmp/new_cluster_dump.json
fi
# Create the pools
bin/ceph osd pool create rbd
bin/ceph osd pool application enable rbd rbd
[ -z "$NUM_RBD_IMAGES" ] && NUM_RBD_IMAGES=1
for (( i=0; i<$NUM_RBD_IMAGES; i++ )); do
bin/rbd create --size ${RBD_SIZE} rbd/fio_test_${i}
rbd du fio_test_${i}
done
bin/ceph status
bin/ceph osd dump | grep 'replicated size'
# Show a pool’s utilization statistics:
rados df
# Turn off auto scaler for existing and new pools - stops PGs being split/merged
bin/ceph osd pool set noautoscale
# Turn off balancer to avoid moving PGs
bin/ceph balancer off
# Turn off deep scrub
bin/ceph osd set nodeep-scrub
# Turn off scrub
bin/ceph osd set noscrub
这是集群创建后显示的默认池的示例。请注意默认的副本集,因为 Crimson 尚不支持 Erasure Coding。
pool 'rbd' created
enabled application 'rbd' on pool 'rbd'
NAME PROVISIONED USED
fio_test_0 10 GiB 0 B
cluster:
id: da51b911-7229-4eae-afb5-a9833b978a68
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 97s)
mgr: x(active, since 94s)
osd: 8 osds: 8 up (since 52s), 8 in (since 60s)
data:
pools: 2 pools, 33 pgs
objects: 2 objects, 449 KiB
usage: 214 MiB used, 57 TiB / 57 TiB avail
pgs: 27.273% pgs unknown
21.212% pgs not active
17 active+clean
9 unknown
7 creating+peering
pool 1 '.mgr' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode off last_change 15 flags hashpspool,nopgchange,crimson stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 7.89
pool 2 'rbd' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode off last_change 33 flags hashpspool,nopgchange,selfmanaged_snaps,crimson stripe_width 0 application rbd read_balance_score 1.50
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.mgr 449 KiB 2 0 6 0 0 0 41 35 KiB 55 584 KiB 0 B 0 B
rbd 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
total_objects 2
total_used 214 MiB
total_avail 57 TiB
total_space 57 TiB
noautoscale is set, all pools now have autoscale off
nodeep-scrub is set
noscrub is set
运行 FIO ¶
我们通过独立工具编写了一些基本的基础设施来驱动 FIO,Linux 灵活 I/O 激励器。所有这些工具都可以在我的 github 项目仓库 这里 公开获取。
本质上,这个基本基础设施包括
一组预定义的 FIO 配置文件,用于不同的工作负载(随机 4K 写入、随机 4K 读取;顺序 64K 写入、顺序 64K 读取)。这些可以根据需要自动生成,特别是对于多个客户端、多个 RBD 卷等。
一组性能测试配置文件,即 响应延迟曲线,它生成不同 I/O 深度范围内的吞吐量和延迟测量结果,并集成资源利用率。我们还可以生成快速 延迟目标 测试,这对于识别给定延迟目标的最大 I/O 吞吐量非常有用。
一组监控例程,用于测量 FIO 客户端和 OSD 进程的资源利用率(CPU、内存)。我们使用
top命令,并通过jc解析输出以生成 .json 文件。我们将它与 FIO 输出集成到一个 .json 文件中,并动态生成 gnuplot 脚本。我们还拍摄测试之前和之后的 diskstats 快照,并计算差异。我们还聚合 FIO 跟踪,以 gnuplot 图表的形式呈现。
点击查看 FIO 执行。
- 我们使用
iodepth选项来控制发出的 I/O 请求的数量。由于我们对 响应延迟曲线(也称为曲棍球棒性能曲线)感兴趣,因此我们从 1 到 64 遍历。我们使用每个 RBD 卷一个作业(但如果需要也可以是可变的)。
# Option -w (WORKLOAD) is used as index for these:
declare -A m_s_iodepth=( [hockey]="1 2 4 8 16 24 32 40 52 64" ...)
declare -A m_s_numjobs=( [hockey]="1" ... )
- 作为初步步骤,我们使用具有
steadystate选项的写入工作负载预调卷。这可确保在运行实际性能测试之前,驱动器处于稳定状态。我们并行执行客户端,因此执行是并发的。
# Prime the volume(s) with a write workloads
RBD_NAME=fio_test_$i RBD_SIZE="64k" fio ${FIO_JOBS}rbd_prime.fio 2>&1 >/dev/null &
echo "== priming $RBD_NAME ==";
...
wait;
- 在主循环中,我们迭代 I/O 深度数量,并为每个预定义的 workload 运行 FIO 命令。我们还拍摄测试之前和之后的 diskstats 快照,并计算差异。我们收集 FIO 进程以及 OSD 进程的 PID,这将用于监控它们的资源利用率。我们有一个启发式方法,可以在延迟的标准偏差从平均值分散过多时提前退出循环。
重要提示:细心的读者会注意到使用了taskset命令将 FIO 客户端绑定到一组 CPU 核心。这是为了确保 FIO 客户端不会干扰 OSD 进程的反应器。工作负载的执行顺序很重要,以确保可重复性。
for job in $RANGE_NUMJOBS; do
for io in $RANGE_IODEPTH; do
# Take diskstats measurements before FIO instances
jc --pretty /proc/diskstats > ${DISK_STAT}
...
for (( i=0; i<${NUM_PROCS}; i++ )); do
export TEST_NAME=${TEST_PREFIX}_${job}job_${io}io_${BLOCK_SIZE_KB}_${map[${WORKLOAD}]}_p${i};
echo "== $(date) == ($io,$job): ${TEST_NAME} ==";
echo fio_${TEST_NAME}.json >> ${OSD_TEST_LIST}
fio_name=${FIO_JOBS}${FIO_JOB_SPEC}${map[${WORKLOAD}]}.fio
# Execute FIO
LOG_NAME=${log_name} RBD_NAME=fio_test_${i} IO_DEPTH=${io} NUM_JOBS=${job} \
taskset -ac ${FIO_CORES} fio ${fio_name} --output=fio_${TEST_NAME}.json \
--output-format=json 2> fio_${TEST_NAME}.err &
fio_id["fio_${i}"]=$!
global_fio_id+=($!)
done # loop NUM_PROCS
sleep 30; # ramp up time
...
fun_measure "${all_pids}" ${top_out_name} ${TOP_OUT_LIST} &
...
wait;
# Measure the diskstats after the completion of FIO
jc --pretty /proc/diskstats | python3 /root/bin/diskstat_diff.py -a ${DISK_STAT}
# Exit the loops if the latency disperses too much from the median
if [ "$RESPONSE_CURVE" = true ] && [ "$RC_SKIP_HEURISTIC" = false ]; then
mop=${mode[${WORKLOAD}]}
covar=$(jq ".jobs | .[] | .${mop}.clat_ns.stddev/.${mop}.clat_ns.mean < 0.5 and \
.${mop}.clat_ns.mean/1000000 < ${MAX_LATENCY}" fio_${TEST_NAME}.json)
if [ "$covar" != "true" ]; then
echo "== Latency std dev too high, exiting loops =="
break 2
fi
fi
done # loop IODEPTH
done # loop NUM_JOBS
基本的监控例程如下所示,它在 FIO 进展的同时并发执行。
fun_measure() {
local PID=$1 #comma separated list of pids
local TEST_NAME=$2
local TEST_TOP_OUT_LIST=$3
top -b -H -1 -p "${PID}" -n ${NUM_SAMPLES} >> ${TEST_NAME}_top.out
echo "${TEST_NAME}_top.out" >> ${TEST_TOP_OUT_LIST}
}
我们为 top 编写了一个自定义配置,因此可以获取有关父进程 ID、线程上次执行的 CPU 等信息(这些信息通常默认情况下不显示)。我们还计划扩展 jc 以支持单个 CPU 核心利用率。
我们扩展并实现了 CBT(Ceph 基准测试工具)中的新工具,作为独立工具,因为它们可以在本地笔记本电脑以及客户端端点中使用。进一步的概念验证正在进行中。
性能结果和比较 ¶
在本节中,我们展示了三种 CPU 分配策略在三种对象存储后端上的性能结果。我们展示了 8 个 OSD 和 5 个反应器的配置结果。
- 重要提示:由于这些结果基于单节点集群,并且受到所用硬件的性质和限制,因此这些结果应被视为实验性的,因此不能用作最终参考。
有趣的是,没有一种 CPU 分配策略比其他策略具有显着优势,但有些工作负载似乎从不同的 CPU 分配策略中受益。对于大多数工作负载,结果在不同的对象存储后端上保持一致。
响应延迟曲线扩展了 yerror 条,描述了延迟的标准偏差。这对于观察延迟如何从平均值(即平均延迟)分散开来很有用。对于所有显示的结果,我们禁用了上述启发式方法,因此我们看到所有数据点(从 iodepth 1 到 64)如请求的那样。
对于每个工作负载,我们展示了三种 CPU 分配策略在三种对象存储后端上的比较。最后,我们比较了单个 CPU 分配策略在三种对象存储后端上的结果。
随机 4K 读取 ¶
Cyanstore ¶

点击查看 CPU 和内存利用率。
我们首先展示 OSD 进程和 FIO 客户端的 CPU 和内存利用率。
- 有趣的是,观察到默认 CPU 分配策略比平衡的 CPU 分配策略具有更高的内存利用率,但仅限于 Cyanstore,因此不应引起关注。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Seastore ¶

点击查看 CPU 和内存利用率。
- 看到 OSD 进程在所有 iodepth 上保持恒定的内存利用率是一个好迹象。NUMA 插槽策略仅比其他策略高出 .6%,这并不重要,不会引起关注。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Bluestore ¶
- 有趣的是,NUMA 插槽平衡的 CPU 分配策略似乎比其他 CPU 分配策略对 Bluestore 具有略微优势。

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
随机 4K 写入 ¶
- 这是一个令人愉悦的工作负载,因为资源利用率图是平滑的,具有温和的梯度。对于 Cyanstore 和 Seastore,NUMA 插槽策略比其他策略略有优势,但默认策略对 Bluestore 略有优势。
Cyanstore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Seastore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Bluestore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
顺序 64K 读取 ¶
- 似乎这种工作负载的性质导致 CPU 利用率出现突发活动。这在所有三种 CPU 分配策略以及所有三种对象存储后端上都是一致的。值得进一步调查。
Cyanstore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Seastore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Bluestore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
顺序 64K 写入 ¶
- 很难解释三种 CPU 分配策略在所有三种对象存储后端上 CPU 利用率的初始峰值。我们可能需要运行该测试的本地版本以进行确认。
Cyanstore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Seastore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
Bluestore ¶

点击查看 CPU 和内存利用率。
| OSD CPU | OSD 内存 |
|---|---|
 |  |
| FIO CPU | FIO 内存 |
|---|---|
 |  |
三种对象存储后端上默认 CPU 分配策略的比较 ¶
我们简要展示了三种存储后端上默认 CPU 分配策略的比较。我们选择默认 CPU 分配策略是因为它是当前领域/社区中使用的策略。
- Cyanstore 在随机读取 4k 和顺序写入 64K 方面表现更高,这很有道理,因为内存访问中没有延迟。
- Bluestore 在随机写入 4k 方面表现更高,这有点令人惊讶。值得进一步调查以找出为什么 Bluestore 在写入小块时效率更高。
- 同样令人惊讶的是,对于顺序 64K 读取,Bluestore 似乎比纯 Reactor 对象后端领先一个数量级。值得仔细检查以验证是否存在任何错误。
| 随机读取 4K | 随机写入 4k |
|---|---|
 |  |
| 顺序读取 64K | 顺序写入 64k |
|---|---|
 |  |
结论 ¶
在这篇博文中,我们展示了三种 CPU 分配策略在三种对象存储后端上的性能结果。有趣的是,没有一种 CPU 分配策略明显优于现有的默认策略,这有点令人惊讶。请注意,为了保持严谨的方法,我们使用了相同的 Ceph 构建(带有上面引用的提交哈希)在所有测试中,以确保每个步骤只修改一个参数,如适当。因此,这些结果尚未代表最新的 Seastore 开发进展。
这是我的第一篇博文,希望对您有所帮助。我非常感谢 Ceph 社区的支持和指导,在我成为这样一个充满活力的社区的一员的第一年里,特别是 Matan Breizman、Yingxin Cheng、Aishwarya Mathuria、Josh Durgin、Neha Ojha 和 Bill Scales。我期待下一篇博文,我们将在其中深入研究 Crimson OSD 中性能指标的内部原理。我们将尝试使用火焰图来分析主要代码地标,并利用现有工具来识别每个组件的延迟。