自动分层 Ceph 对象存储 - 第一部分
与 S3 兼容的对象存储系统通常具有将对象存储到不同分层的功能,这些分层具有不同的特性,因此您可以获得最佳的成本和性能组合,以匹配任何给定应用程序工作负载的需求。存储分层在 S3 术语中称为“存储类”,AWS 中的示例存储类包括“STANDARD”用于通用用途,以及“DEEP_ARCHIVE”和“GLACIER”等较低存储类,用于备份和归档用例。
Ceph 的 S3 兼容存储功能还包括创建自己的存储类的能力,并且默认情况下它会自动创建一个名为“STANDARD”的单个存储类,以匹配 AWS 提供的默认分层。
在这篇由 3 部分组成的博文系列中,我们将深入研究 Ceph 的自动分层对象存储,并探讨其中的一些 Lua 脚本编写,我认为即使您以前没有使用过或听说过 Lua,您也会觉得它易于上手。
- 第一部分 - Ceph 对象存储基础知识以及为什么您需要设置不同的存储类
- 第二部分 - 如何使用 Lua 脚本根据大小自动将对象分配到不同的存储类
- 第三部分 - 更多高级 Lua 脚本,根据对象名称的正则表达式匹配动态地将对象匹配到存储类
Ceph 对象存储基础知识
Ceph 对象存储集群由两个主要的存储池组成,一个用于元数据,一个用于数据。
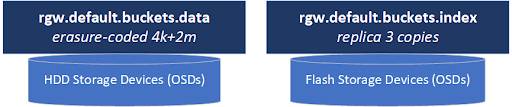
元数据池存储每个存储桶中所有对象的索引,并且名称中包含“rgw.bucket.index”。本质上,存储桶索引池是一个数据库集合,每个存储桶一个,包含该存储桶中每个对象及其构成每个 S3 对象的数据块(RADOS 对象)的位置信息。
数据池通常在名称中包含“rgw.buckets.data”,它们存储构成集群中每个 S3 对象的实际数据块(RADOS 对象)。
存储桶索引池中的元数据需要位于快速存储上,该存储非常适合小读写(IOPS),因为它本质上是一个数据库集合。因此(以及出于本文以外的各种技术原因),此池必须配置为副本布局,并且理想情况下应存储在全闪存存储介质上。闪存存储对于存储桶索引池也很重要,因为存储桶必须定期调整其存储桶索引数据库(基于 RocksDB)的大小,以腾出更多空间来存储更多对象元数据,因为存储桶增长。此过程称为“重新分片”,并且所有这些都自动在后台发生,但是如果存储桶索引池位于 HDD 介质而不是闪存介质上,重新分片可能会大大影响集群性能。
相反,数据池(例如 default.rgw.buckets.data)通常存储可以有效地写入 HDD 的大型数据块。这就是擦除编码布局发挥作用并为您提供可用容量的大幅提升(通常为 66% 或更多,而使用 replica=3 时为 33% 可用容量)。当您使用足够大的对象(通常为 4MB 及更大,但理想情况下为 64MB 及更大)时,擦除编码还具有出色的写入性能,因为使用擦除编码时的网络写入放大程度较低(客户端 N/S 流量的 ~125%)与基于副本的布局(客户端 N/S 流量的 300%)。

对象存储区域和区域组
一个区域包含所有 S3 对象的完整副本,这些副本可以全部或部分地镜像到其他区域。当您想将所有内容镜像到另一个区域时,您会将想要镜像的区域放在一个区域组中。通常,区域组的名称也是 S3 领域,例如“us”或“eu”,而区域将具有类似于从一些常见的 AWS 区域名称借用的名称,例如“us-east-1”或“us-west-1”。当您将 Ceph 对象存储设置为与 Veritas Netbackup 等产品一起使用时,我们建议使用类似于“us-east-1”的 AWS 区域名称,以获得兼容性,因为某些产品专门查找已知的 AWS 区域和领域名称。一个具有区域“us-east-1”和区域组(和领域)的“us”的集群如下所示。

对象存储类
存储类为我们提供了一种将对象标记到我们选择的数据池中的方法。当您使用单个数据池设置集群时,如上所示,您将拥有一个映射到它的单个存储类,称为“STANDARD”,并且您的集群将如下所示。

通过多个存储类进行自动分层
现在我们来到了本文的核心。如果您的所有数据都不由大型对象组成,如果您有数百万或数十亿的小对象与大型对象混合在一起怎么办?您希望对大型对象使用擦除编码,但对于小型对象(例如 1K 到 64K)来说,这将是浪费和昂贵的。但是,如果您将 replica=3 作为数据池的布局,您将只能获得 33% 的可用容量,并且您将耗尽空间并需要三倍的存储空间。这就是多个数据池发挥作用的地方。在不购买任何额外存储的情况下,我们可以与现有的池共享基础介质(OSD),并创建新的数据池,以便为我们提供额外的布局选项。以下是一个示例,我们添加了两个额外的 data pool 和相关的存储类,我们将称之为 SMALL_OBJ 用于小于 16K 的对象,MEDIUM_OBJ 用于 16K 到 1MB 的所有对象,如下所示

因此,现在我们有一个存储类“SMALL_OBJ”,它将仅使用几千兆字节的每百万小对象,并且能够有效地读取和写入这些对象。我们还有一个基于 HDD 的“MEDIUM_OBJ”存储类,它也像“SMALL_OBJ”一样使用 replica=3 布局,但此池位于 HDD 介质上,因此成本更低,并允许我们合理地将大约一百万个 1MB 对象存储在 1TB 的空间中。对于其他所有内容,我们将将其路由到我们的基于擦除编码的默认“STANDARD”存储类。请注意,某些为 AWS S3 编写的应用程序不会接受像“SMALL_OBJ”这样的自定义存储类名称,因此如果您遇到兼容性问题,请尝试从AWS 使用的预定义存储类名称中进行选择。
用户不瞄准
好的,您已经完成了以上所有操作,您拥有一个配置最佳的对象存储集群,但现在您的用户打电话说它很慢。所以您进行了调查,发现您的用户没有努力将他们的对象分类到正确的存储类类别中(即通过设置 S3 X-Amz-Storage-Class 标头)进行上传。这就像试图让每个人都整理和分离他们的回收利用一样。但是,在这种情况下,我们有一种秘密武器,那就是 Lua,在下一篇文章中,我们将使用几行脚本将我们的对象放入正确的存储类,这样用户就不需要做任何事情。
(遵循回收箱的类比,我们将能够只是将对象朝垃圾箱的方向扔去,它总是会落入正确的垃圾箱中。无需瞄准,就像 Stuff Made Here 中的 Shane 一样! 😀)