Ceph OSD CPU 伸缩 - 第一部分
简介
Ceph 在很多方面都做得很好,但它从来不以资源消耗极低而闻名。确保数据一致并安全地放置到需要的位置需要付出努力。我们正在进行多项工作来优化 Ceph 的数据路径,但事实是,Ceph 历史上需要大量的 CPU 才能在快速存储设备(如 NVMe 驱动器)上实现高性能。今年夏天,一位用户联系了我们的团队,对低 CPU 核心数下的性能表示担忧。他们被建议在使用 NVMe 驱动器时,应为每个 OSD 分配 2 个核心。该建议没有解释原因。他们决定购买硬件,但只有一半的 NVMe 驱动器托架已填充(即,每个 OSD 可用 4 个核心)。在这种配置下,性能是可以接受的,但用户有理由担心,当他们完全填充服务器中的 NVMe 驱动器时会发生什么。不幸的是,我不得不告诉他们,他们可能只会看到容量增加,而不会看到性能增加。最初的建议并非完全没有道理。如果用户主要不关心小随机 IO 的性能,那么每个 OSD 2 个核心可能是一个不错的价值主张。在 NVMe 驱动器上运行 Ceph 除了提高小随机 IO 性能之外,还有许多好处。但是,对于这位用户来说,小随机 IO 是一个问题,而这正是 CPU 资源最重要的时刻。
不幸的是,这并不是第一次出现这个问题,并且围绕这个话题存在很多困惑。两年前,我们更新了上游 Ceph 文档,试图在 这个 PR 中提供更好的指导。当时,我们的大致指导是(在复制之前!)
- 每 200-500 MB/s 1 个核心
- 每 1000-3000 IOPS 1 个核心
但这里最重要的方面是 IOPS 性能。本文将重点介绍 Ceph 小随机 IOPS 性能如何随着 CPU 资源的增加而扩展。
集群设置
| 节点 | 10 x Dell PowerEdge R6515 |
|---|---|
| CPU | 1 x AMD EPYC 7742 64C/128T |
| 内存 | 128GiB DDR4 |
| 网络 | 1 x 100GbE Mellanox ConnectX-6 |
| NVMe | 6 x 4TB Samsung PM983 |
| 操作系统版本 | CentOS Stream release 8 |
| Ceph 版本 | Pacific V16.2.9(从源代码构建) |
所有节点都位于同一 Juniper QFX5200 交换机上,并通过单个 100GbE QSFP28 链路连接。集群是使用 CBT 构建的,并且 fio 测试是使用 librbd 引擎执行的。Intel 系统上一个重要的操作系统级别优化是将 tuned profile 设置为“latency-performance”或“network-latency”。这主要通过避免与 CPU C/P 状态转换相关的延迟峰值来帮助。基于 AMD Rome 的系统似乎对这方面不太敏感,但是,tuned profile 仍然设置为“network-latency”用于这些测试。
测试设置
CBT 被配置为使用一些修改后的设置部署 Ceph,而不是默认设置。主要的是,rbd 缓存被禁用,每个 OSD 被赋予 8GB 的内存目标,并且 msgr V1 被使用,cephx 被禁用。在最近的测试中,我们已经看到 Msgr V2 配合默认的 cephx 身份验证表现相似,但启用线路加密可能会导致服务器和客户端的性能下降高达 30-40%,同时 CPU 使用率也更高。Fio 被配置为首先使用大写填充 RBD 卷,然后进行 3 次迭代的 4K 随机读取,然后进行 4K 随机写入,iodepth=128,持续 5 分钟。CBT 允许 OSD 被其他程序或环境变量包装,并且 numactl 被用于控制系统上 OSD 可以使用多少个核心。最初的测试是用单个 OSD 和 1X 复制执行的。多 OSD 测试是用多个 OSD 和 3x 复制执行的。
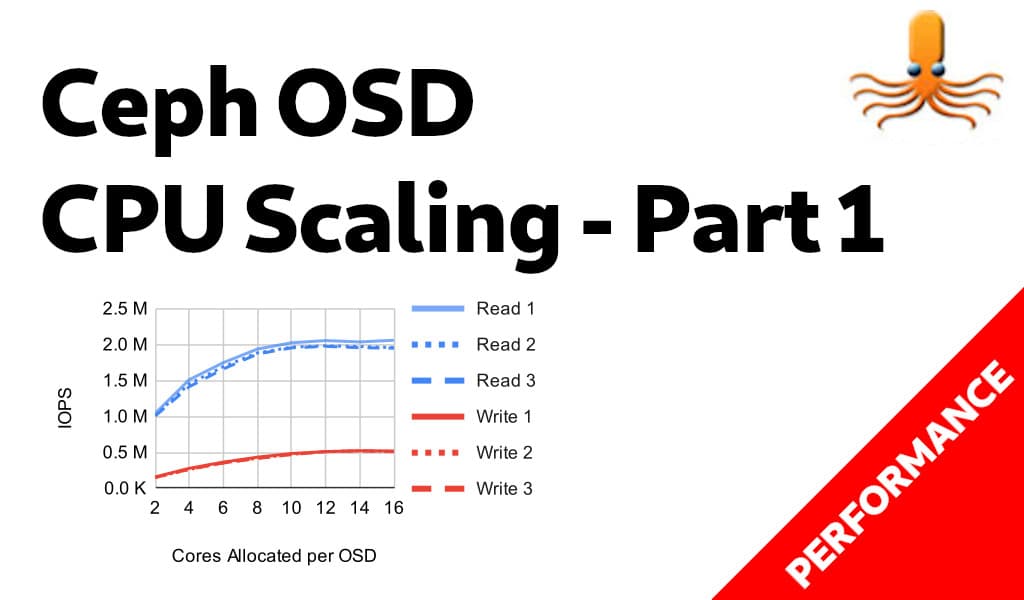
单个 OSD 测试
在多 OSD 集群中,Ceph 以伪随机方式确定性地放置数据。在给定时间可能会出现热点。有些 OSD 的工作量会比其他 OSD 多,并且聚合性能可能会因此受到影响。最终,整个集群的性能受限于集群中最慢 OSD 的性能。针对单个 OSD 进行测试消除了这种行为,并进一步消除了额外的复制延迟和开销,确保 OSD 在最佳效率下工作。测试单个 OSD 并不能代表实际集群可以做的事情,但它确实显示了在最佳条件下给定 OSD 可以执行的性能如何。

首先要注意的是,性能在 2 个和 4 个核心之间增加了大约 100%。几乎是线性提升。但是,在 4 个核心之后,收益开始减慢。从 4 个到 16 个核心只会再增加 100%,收益几乎完全稳定在 10 个核心。写入性能的扩展更高,在 14-16 个分配的核心处达到顶峰,约为 350%。但是,Ceph OSD 真的在使用这些测试中的所有核心吗?

事实证明,分配更多的核心给 OSD 可以持续提高性能,直到 14-16 个核心,但在高核心数下,OSD 不会持续使用它们分配的所有核心。这对于读取尤其如此。更多的核心意味着更高的性能,但效率会随着核心数的增加而降低。但是,每个核心使用的 IOPS 保持相对平稳。为什么会这样,限制是什么?默认情况下,Ceph OSD 有 80 多个线程,但从资源消耗的角度来看,最重要的线程是
- 16 个 OSD 工作线程(每个包含 2 个线程的 8 个分片)
- 3 个异步 messenger 线程
- 1 个 bluestore key/value 线程
- 1 个 bluestore “finisher” 线程
- RocksDB 刷新(高优先级)和压缩(低优先级)后台线程
在不深入细节的情况下(我们将在后续博文中保存),库存 OSD 的实际最大核心使用量可能约为 23 个核心。我们在实验室中获得的最高使用率,在库存线程计数下,在 5 分钟的时间内约为 18-19 个核心,用于 4K 随机写入,并且对 OSD 施加了限制,并且禁用了 RocksDB 的写前日志。所以我们为什么在这些测试中看不到这一点?可能的原因是 Ceph 根本无法一直让所有 16 个工作线程保持繁忙。也就是说,在工作线程可以执行更多工作之前,会有短暂的时间等待。虽然 OSD 平均可能使用 6 或 8 个核心,但它可能在短时间内爆发到 16+ 个核心,而其他时候可能只需要 3-4 个核心。这是在裸机上运行 Ceph 可能比在容器或虚拟机中运行 Ceph 具有优势的一种情况,如果施加了硬核心限制。
60 个 OSD 集群测试
在部署完整集群时,单个 OSD 测试中观察到的趋势会发生吗?

在查看 60 个 OSD 集群测试结果时,有几点立即显现出来。虽然曲线看起来与单个 OSD 测试相似,但读取和写入的性能在每个 OSD 上最多为 8-10 个核心,在写入时最多为 12 个核心。在单个 OSD 测试中,读取和写入收益分别达到约 200% 和 350%。在完整的集群配置中,收益分别达到 100% 和 250%。

仅查看 OSD.0,看起来较大集群中的 OSD 正在随机读取测试中利用更少的核心。同时,每个分配的核心和每个使用核心的 IOPS 数字也低得多。在写入端,现在正在使用 3x 复制。为了与单个 OSD 测试进行比较,我们必须查看考虑到复制的 OSD 传递的 IOPS。即使这样,每个核心的写入性能也比单个 OSD 测试低得多。好消息是,文档中的估计值似乎是有效的。在读取端,Ceph 正在传递每使用核心约 7500 IOPS,具体数字取决于分配给 OSD 的核心数,从 2400 到 8500 IOPS 不等。在写入端,Ceph 正在传递每使用核心约 3500 IOPS,从 1600 到 3900 IOPS 不等。这些数字比我们两年前声称的略好,并且我们在最近的 Quincy 版本中取得了进一步的改进。
单个 OSD 与多 OSD NVMe 性能
另一个经常出现的问题是 Ceph 可以很好地利用 NVMe 驱动器。通常,这伴随着对直接写入本地连接驱动器的进行基准测试,用户想知道为什么 Ceph 速度较慢,尽管它由更多的驱动器支持。简而言之,Ceph 确实比直接写入磁盘慢,并且有许多原因。
- 计算 crush 放置、校验和、加密、纠删编码、网络开销等引入的延迟
- 处理数据(编码/解码等)以及在线程之间以及 RocksDB 中分配/复制/移动数据。
- Ceph 不仅写入数据,还写入关于该数据的元数据。在执行小写入时,这可能非常重要。
- 允许线程在没有工作时进入睡眠状态,并在有工作时唤醒它们。这样做是为了减少空闲期间的 CPU 开销,但如果线程太快地进入睡眠和唤醒状态,则会对性能产生重大影响。后续博文将更详细地讨论这一点。
其中一些事情很难在没有大量工作的情况下改进。Ceph 始终受到网络通信和处理网络堆栈的限制(尽管 dpdk 可以提供帮助)。Crush 总是会引入一些延迟来确定数据所在的位置,并且始终会有一定程度的额外延迟由 crc32、编码/解码等引起。话虽如此,单个 OSD 和多 OSD 测试之间存在很大的性能差异。

查看这些图表有点粗糙。即使 60 个 OSD 集群正在传递大约 200 万个随机读取 IOPS,但单个 OSD 仍然能够以更高的效率传递几乎 4 倍的每个 NVMe 性能。在写入端,情况略有接近,但单个 OSD 仍然快约 2 倍。但是,并非一切都丢失了。在 Ceph Quincy 中,我们努力改进写入路径性能。在 Ceph Quincy 版本中的改进和选择性 RocksDB 调整之间,我们实现了与库存 Ceph Pacific 安装相比,4K 随机写入 IOPS 提高了 40% 以上。

要了解我们获得这些结果的方式,请参阅 RocksDB 调整深入博文 此处。
结论
最终,在集群级别和 OSD 内部,仍然有很大的提升性能空间。在未来的博文中,我将深入探讨一些限制低核心数和高核心数性能的问题,以及 Ceph 可以进一步改进的想法。在此之前,在选择为 NVMe 驱动的 OSD 分配多少核心时,存在一些权衡。每个 OSD 2-4 个核心时,Ceph 大部分可以利用所有核心进行小读和小写。添加额外的核心(甚至每个 OSD 16+ 个)可以提高性能,但每个添加的核心带来的收益会降低。每个使用的核心的效率保持相对恒定,但当分配更高的核心数时,OSD 在任何时候充分利用所有可用核心的一致性会降低。这会影响最初的购买决策,也会影响基础设施决策,例如电源和冷却,甚至关于容器/VM 资源利用率限制的决策。
最后,这篇文章重点介绍了 Ceph Pacific,但 Ceph 的效率和顶级性能自那时起已经得到了提高。这些曲线对于 Quincy 来说可能看起来略有不同,并且对于 Reef 来说几乎肯定会再次不同。这些测试也在一个全新的集群上运行,可能不会在具有大量老化数据的完整集群上看起来相同。然而,我希望这篇文章至少提供了一个起点,说明 CPU 资源如何影响现代 NVMe 驱动上的 Ceph。感谢阅读!