深入探索
IDC DataAge 白皮书评估了数据的生成位置、存储位置、按介质类型的字节出货量以及大量其他信息。白皮书中的以下图表说明了数据如何流向核心,并在核心达到最高浓度。
数据存在的地方,就会有计算能力来提取见解。鉴于核心处的高数据集中度,看到核心处通用计算的最高集中度也就不足为奇,因为大量数据在核心处被聚合、过滤、索引和编目。在核心处,计算和存储的解耦已经很常见,无论是在本地还是在公有云中。随着GPU、FPGA和TPU等专用计算硬件的普及,计算和存储解耦的趋势预计将加速。在解耦的数据架构中,数据主要持久存储在专用的对象存储系统或服务中。
在2018年关于大数据对象存储的采访中,Cloudera前首席技术官Mike Olson使用了“完全自动化”来描述致力于Ceph的人们。如今,像马萨诸塞州开放云这样的组织和倡议正在利用Ceph对象存储作为核心,既作为数据湖,又是解耦数据仓库的一部分。
解耦的数据仓库通常不过是数据湖的一个更整洁的区域,而“湖仓”一词有时用于区分与过去“先写模式”数据仓库的模式。除了分析之外,我们开始看到一种模式,即组织为更精炼的数据创建主页,其中表示机器学习特征的标量和向量存储;离线特征存储。有趣的特征从实时系统、数据湖和数据仓库中提取和/或计算,然后以Petastorm(Uber的Petastorm)或Tensorflow的TFRecord(Tensorflow的TFRecord)等格式加载到离线特征存储中。
特征存储模式将特征提取与消耗解耦。持久化计算后的特征保留了用于训练特定模型的精确输入,并且进一步成为可以用于开发其他模型的数据产品。值得注意的是,即使特征是从数据湖或仓库中的数据计算得出的,拥有一个为离线特征存储量身定制的解决方案也可能是有益的,因为它有助于确保来自训练和批量推理的负载不会干扰数据处理和分析工作负载。
Penguin Computing、Seagate和Red Hat最近合作开发了Penguin Computing DeepData with Red Hat Ceph Storage。在追求此解决方案的过程中,我们探索了各种技术,以最大限度地提高Ceph对象存储作为离线特征存储的吞吐量、成本效益和可扩展性。我们的测试结果表明,Ceph对象存储非常适合深度学习任务,例如直接训练、批量推理或快速将大量特征数据材料化到用于实时推理的低延迟键值存储中。
高吞吐量 ¶
实现大多数存储系统高吞吐量的关键是确保数据请求大小足够大,以摊销请求的开销。现在,越来越多的组织正在设计将特征聚合到以兆字节为单位的流式或列式数据集中的特征提取管道。 TFrecord教程详细介绍了跨多个数据文件分片数据,文件大小不小于10 MB,理想情况下为100 MB或更大。一个很好的流式数据集用法的例子在这个工具中被捕捉到,它将ImageNet数据集转换为TFRecord,为像ResNet或MaskRCNN这样的模型进行训练和验证做准备。直接训练和批量推理所需的吞吐量是预期同时运行在特征数据分割上的GPU核心数量的函数。训练或推理集群越大,存储系统所需的吞吐量就越高。
成本效益 ¶
是什么使存储系统具有成本效益?低单位可用存储成本以及低单位性能成本,或者在本例中,低吞吐量成本。容量需求由特征量决定。所需吞吐量与存储容量的比率是确定特定存储介质的适当性和成本效益的有用指标。Google白皮书用于数据中心的磁盘提出了凸包的概念来帮助介质选择。在Google论文中,存储设备的$/GB (y) 与 IOPS/GB (x) 被绘制成图,作者建议对于特定的IOPS/GB目标,最佳的数据中心存储组合由红色的下凸包形成,如图所示的概念图。
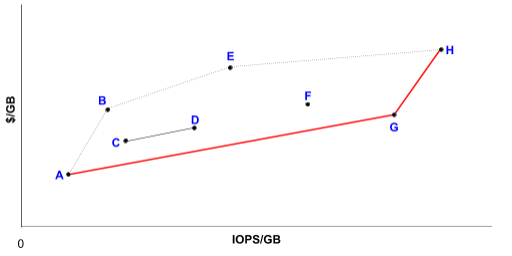
图2。给定IOPS/GB的最佳存储组合以红色显示(来源:Google,2016年《用于数据中心的磁盘》)
目前,旋转磁盘在y轴($:GB)上低于固态替代品。自发表该论文以来,没有证据表明SSD容量的增长速度(具有足够的程序擦除周期)超过了HDD容量的增长速度。媒体选择的另一个必要考虑因素是耐用性。频繁过期和摄取新数据的存储需要更高耐用性的媒体类型。耐用性和成本优势促使我们开发了一种使用旋转磁盘进行对象数据的解决方案。
可扩展性 ¶
直到最近,我们看到大多数大型且更先进的组织都在检查专门用于离线特征存储的存储系统。通过检查他们当前正在处理的特征数据量,我们可以预测他们未来的需求以及后续组织的需求。
作为一个说明性的例子,让我们考虑特斯拉的Dojo超级计算机正在使用的特征数据量。公开信息很少,但在特斯拉自动驾驶日(2019年4月),我们确实了解了用于训练和验证自动驾驶汽车模型所使用的特征数据量。Stuart Bowers透露,两年前他们已经捕获了超过7000万英里的(1.12亿公里)特征数据。这些特征数据用于开发一系列使特斯拉车辆在自动驾驶模式下能够在高速公路上变道行驶的模型。随着他们通过受控部署计划增加特征量,他们能够开发出更好的模型,从而实现更果断的变道行驶。
在美国,广告的每加仑英里数(MPG)统计数据是通过在测功机上测试新车辆来确定的。车辆在捕获高速公路MPG统计数据时以平均每小时48英里的速度行驶。如果我们将7000万英里除以48,我们得到大约150万小时的特征数据,这些数据是从8个摄像头、12个声纳、1个雷达、gps以及踏板/方向盘角度传感器生成的数据。这有很多原始数据,您可以从原始数据中提取的特征数量可能会超过原始数据容量要求,如果所有特征数据都保留用于模型可解释性、漂移检测和为未来的模型开发提供信息的话。
在Google的GPT-3论文中,我们了解到近5000亿个特征(n-gram标记)被用于训练所有8个GPT-3模型变体。在Facebook的SEER论文中,我们了解到模型是使用20亿张图像进行训练的。如果您考虑SEER模型的复杂性/容量,它可以提取的关于自动驾驶车辆正在导航的世界的向量空间的信息确实非常出色。
解决方案 ¶
如图2所示的堆叠面积图,我们能够从用于我们测试的10节点Ceph集群中实现高达79.6 GiB/s的聚合吞吐量。堆叠中的每一层代表来自8个客户端机器随机读取整个对象的数据吞吐量,对象组成3.5亿个合成数据集。
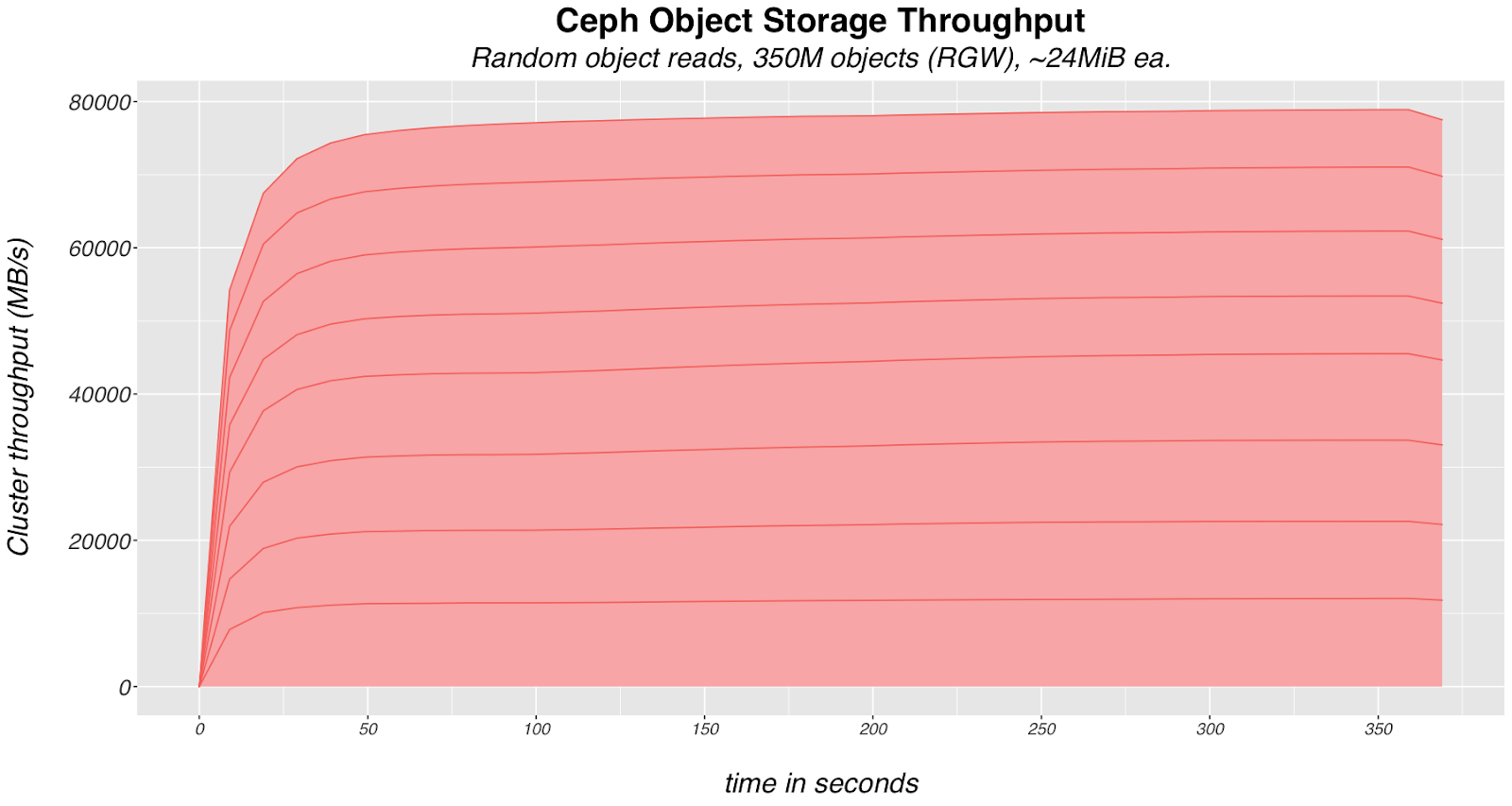
图2。使用24MiB对象进行随机对象读取操作的Ceph对象吞吐量。
存储节点使用TLC SSD进行元数据(块分配、校验和、bucket索引),并直接连接到1:1的Seagate Exos E存储机箱,其中包含84个高容量企业级硬盘驱动器用于对象数据(Seagate Exos X16 16TB SAS)。我们结合这些驱动器与Ceph高效的擦除编码,以最大限度地提高成本效益。提取每个可用的容量对于大规模应用尤其重要,为了支持这个目标,我们首先从假设集群即使在接近90%磁盘利用率时也能保持性能良好的前提开始我们的优化工作。在我们开始吞吐量测试之前,集群利用率的概览
| 原始存储: 类别 大小 可用 已用 原始已用 %原始已用 hdd 12 PiB 1.5 PiB 11 PiB 11 PiB 87.49 总计 12 PiB 1.5 PiB 11 PiB 11 PiB 87.49 池: 池 ID 存储 对象 已用 %已用 最大可用 default.rgw.buckets.data 45 7.8 PiB 350.00M 10 PiB 92.79 623 TiB |
离线特征存储可以使许多存储系统达到极限,为了确保它能够胜任这项任务,我们一直在突破Ceph的极限。2020年2月,我们加载了一个7节点Ceph集群,其中包含10亿个对象,到9月,我们将我们的测试工作扩展到在6节点Ceph集群中存储100亿个对象。Ceph使用算法放置,因此集群能够存储的对象数量与节点数量成正比。通过扩展到数百个节点,并使用Parquet和TFRecord等格式,Ceph能够保护并提供对数万亿个特征的高吞吐量访问。
接下来是什么 ¶
我们想分享我们的经验,以及我们如何为离线特征存储调整Ceph。我们微调了radosgw、rados擦除编码和bluestore,以共同实现我们的目标。并非我们所做的一切都是直观的,仅仅提供一个ceph.conf文件而不解释我们调整的各种参数的目的以及它们如何交互,我们认为这将是一种失职。相反,我们认为通过一系列博客文章(深入探索)深入研究这些每一层会更有益。敬请期待!