Ceph IO 模式:坏的方面

Ceph IO 模式分析之二:坏的方面。
坏的方面
I.1. 日志记录 ¶
一旦 IO 进入 OSD,它就会被写入两次.
此语句仅涉及日志。
I.1.1. 单次写入... ¶
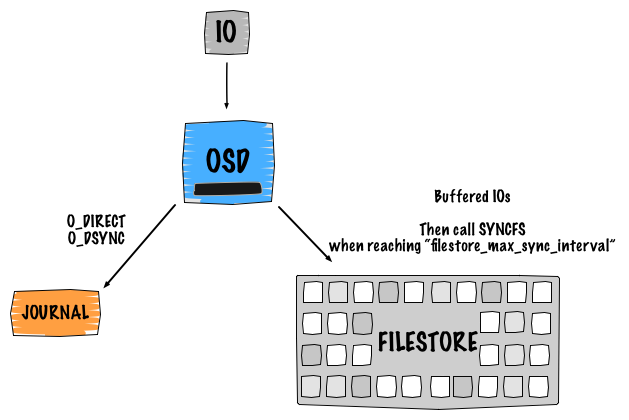
Ceph 是一种软件定义存储,这意味着数据的复制和可用性由软件智能提供和保证。我认为理解 Ceph 的内部工作方式(默认逻辑设计)非常重要。这里的关键点是向您展示在执行写入操作时会发生什么。因此,让我们以具有 2 个副本的单个对象写入为例。这将导致 4 个 IO
- 客户端将请求发送到主 OSD
- 第一个 IO 被写入 Ceph 日志
- 日志使用 libaio 并使用
O_DIRECT和O_DSYNC进行写入。写入使用writev()处理 - 第二个 IO 被写入后端文件系统,使用
buffered_io。写入使用writev()处理 - 当达到
filestore_max_sync_interval时,文件存储调用syncfs并修剪日志,并在syncfs完成后释放锁。
相同的过程重复到辅助 OSD 以进行复制。
I.1.2. 关于日志 ¶
在上一段中,我提到一个日志,但它到底做什么?嗯,它做了许多事情,例如
- 确保数据和事务的一致性。它基本上充当传统的日志文件系统,因此它可以重放内容,如果出现问题。
- 提供原子事务。它跟踪已提交的内容和将要提交的内容。
- 写入日志是顺序进行的
- 作为 FIFO 工作
Ceph OSD 守护程序停止写入并将日志与文件系统同步,允许 Ceph OSD 守护程序从日志中修剪操作并重用空间。
如果 OSD 文件系统是 Btrfs 或 ZFS,则上述语句不适用。通常,我们建议使用 XFS 或 ext4 作为 OSD 文件系统,这使得日志使用 writeahead 模式。我们先写入日志,然后写入后端文件系统。这与 COW(写时复制)文件系统不同,使用 writeparallel 模式。我们同时写入日志和后端文件系统。
I.1.3. 设计缺陷 ¶
显然,您已经注意到使用 writeahead 模式的日志会造成巨大的性能损失,同时写入对象。由于我们写入两次,如果日志存储在与 osd 数据相同的磁盘上,这将导致以下情况
Device: wMB/s
sdb1 - journal 50.11
sdb2 - osd_data 40.25
传统的企业级 SATA 磁盘可以提供大约 110 MB/sec 的顺序写入 IO 模式。所以是的,基本上我们将 IO 分成两半。
为了避免(或隐藏)这种影响,有几种实现日志的方法。
通常,Ceph 日志只是文件系统上的一个文件(在 /var/lib/ceph/osd/<osd-id>/journal 下)。首先,这效率极低,因为文件系统开销很大,其次,我们确切地不知道日志在硬盘驱动器上的位置(文件和块之间的相关性)。
另一种实现方法是在 OSD 数据磁盘的开头使用原始分区。基本上,您只需使用第一个扇区创建一个微小的分区。由于我们位于设备的开头,我们可以确定这是磁盘上最快的区域。边缘总是更快,并且一旦机械臂靠近盘片中心,性能就会开始下降(这是一个众所周知的问题)。如果您不想为日志专门分配一个磁盘,这可能是使用日志的最佳方法。
然后,如果您想提高性能,可以使用单独的旋转磁盘。不幸的是,这不会表现得很好,因为磁盘将花费大部分时间在并发日志写入发生时寻找写入位置(多次日志写入)。
最后,实现日志的最佳方法是使用单独的 SSD 磁盘。这使您能够获得使用 SSD 的常见好处,例如:无寻道、快速顺序写入和快速访问时间。
II. 文件系统碎片 ¶
Ceph 中存储的每个对象都显示为后端文件系统上的一个文件。默认情况下,这些对象位于 /var/lib/ceph/osd/<osd.id>/current/<pg.id>/ 下。由于其分布式性质以及动态集群,Ceph 始终执行写入、更新和对象(此处理解为文件)操作。这种负载对于传统文件系统来说非常繁重,以至于可能会导致大量碎片。显然,效果会随着时间的推移而显现,因为如今,文件系统具有诸如 延迟分配 之类的机制,这些机制倾向于有效地控制文件系统碎片。如果您使用 RBD,虚拟化机器和裸机机器的块设备功能,对象块的大小为 4MB(默认条带)。但是,生活在 Ceph 集群中的每个映像都可以拥有自己的条带和 更多。
注意:文件系统碎片很少被考虑在内,因为它很难模拟老化的文件系统。
在 Ceph 环境中,我们可以公平地说,随着时间的推移,性能将趋于下降。例如,您可以在使用了一年的集群后获得以下结果
bash $ sudo xfs_db -c frag -r /dev/sdd actual 196334, ideal 122582, fragmentation factor 37.56%
幸运的是,Ceph 核心开发人员最近启动了一项正在进行的工作。这个新功能称为 RADOS IO 提示。这将模拟 fadvise(2) 的作用。fadvise(2) 是一个系统调用,可用于向 Linux 提供有关如何缓存文件的提示。因此,内核可以选择适当的预读和缓存技术来访问相应的文件。有关实现细节,请参阅 邮件列表讨论。
III. 没有并行读取 ¶
目前,Ceph 不提供任何并行读取功能,这意味着 Ceph 将始终从主 OSD 提供读取请求。由于我们通常有 2 个或更多副本,因此总体读取性能可以得到显着提高。我回忆起 Ceph 邮件列表上对此进行过讨论,但我找不到任何指针。但是,我确信这是 Ceph 开发人员的 TODO 列表的一部分:)。
IV. 深度清理会杀死您的 IO ¶
清理是对象的 fsck。它检查 PG 级别的对象一致性,并比较副本版本与主对象。
有两种类型的清理
- 轻量级清理(每天)检查对象大小和属性。
- 深度清理(每周)读取数据并使用校验和来确保数据完整性。
许多用户报告说,深度清理对集群产生了重大影响。为了对抗这种 IO 惩罚,这里的选择非常有限,您可以禁用它,但您将独自承担风险并尝试使用 适当的选项 来控制行为。
Ceph 致力于尽可能地保护您的事务和数据安全。显然,这需要付出一定的性能代价。但是,我们已经看到了几种规避这种设计缺陷的技术。下次再见,我们将介绍最后一部分:丑陋的方面。